


Is AI still shit?
A review of my claims from last August.

Last August I launched this blog with a simple statement: “AI is kinda shit”.

It marked the evolution of my thinking about AI in general. From running a school teaching “prompt engineering” for money to openly sharing knowledge and building real solutions instead. So much happened since that I decided it’s time to revisit the claims there.
The four main claims where:
Prompt engineering is useless.
ChatGPT is not leading the market.
The AI revolution is delayed.
AI lacks common sense
Prompt engineering is useless
VERDICT: True
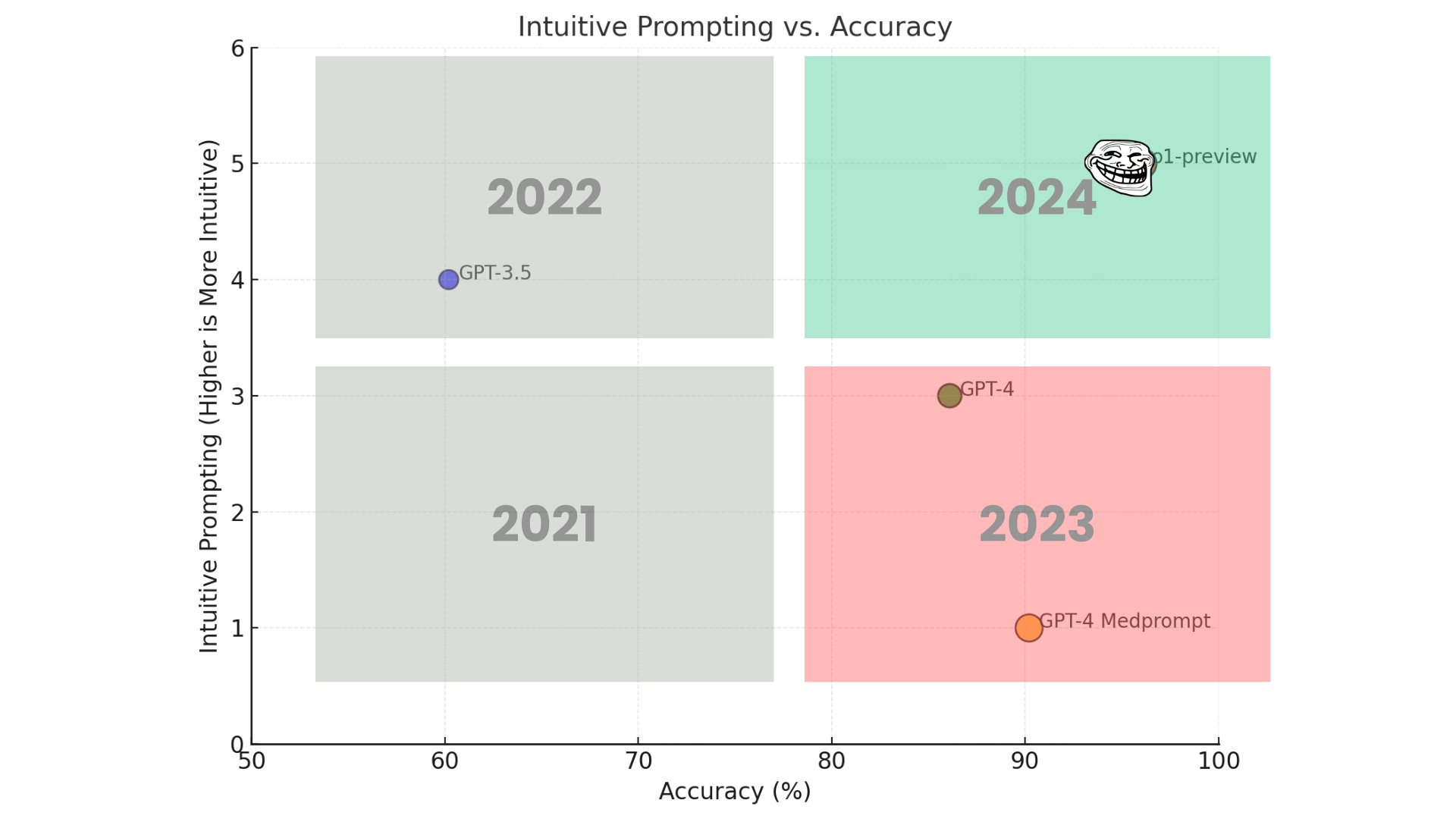
In 2024 November, Microsoft’s research team published a new study where they compared lazily prompted o1-preview’s performance in medical diagnosis tests versus a very well structured GPT-4o prompt template called Medprompt.
o1-preview outperformed Medprompt almost every single time.
I wrote about this in more depths in this article:

ChatGPT is not leading the market
VERDICT: So-so.
This is a bit interesting. ChatGPT surpassed 400 million users as reported by Reuters this February. Sam Altman successfully transformed OpenAI into a product company and they figured out how to maintain user growth making them the market leader on this front. No other company has this level of distribution except Google.
However, that’s not the full picture.
Before OpenAI was a product company, it was a model company. Its primary output was new models that were lightyears ahead of the entire market.
Despite OpenAI’s launch of “reasoning models” with o1 followed by o3-mini and the subsequent launch of GPT-4.5 (touted as the “emotionally intelligent” model, whatever that means) we saw that competitors quickly caught up. Now we have DeepSeek R1, Gemini 2.5 Pro, Gemini Flash Thinking, Claude 3.7 Sonnet, Grok 3 — all capable of surpassing OpenAI’s models in one way or another.
Here’s the latest benchmark:

Then OpenAI launched Deep Research which was then quickly followed by Perplexity’s Deep Research tool and open-source versions, like Jim Le’s n8n workflow.
As Satya Nadella famously said: models are being commoditized.

The AI revolution is delayed
VERDICT: True.
Remember how everyone was predicting sweeping, radical changes? A few years ago you could hear this from everyone. You still hear this, but now mostly from people who have a commercial interest in investors believing that to be still true.
Like Dario Amodei, CEO of Anthropic who claimed that in a year 100% of new code will be written by AI.
Let me explain what the reality is. I regularly run workshops for our clients at Stylers. Yesterday I did a half day event for a room of developers at a large enterprise client on how devs can use AI tools like Cursor or Lovable and what is Prompt-Driven Development (a very comprehensive framework spearheaded by
).But here’s the grim truth:
The company just allowed devs to use Github Copilot. Everything else is strictly banned.
In most companies the use of ChatGPT and other tools are either explicitly forbidden or used via shadow IT (which is just a fancy word of insecure, unsanctioned tech).
Everyone is scared shitless about data security and nobody actually knows what the hell GenAI should actually be used for.
It’s literally my job to figure out the use cases for clients and in the last 3 months I’ve worked on over 15 different use cases from large scale database search to real time cold calling agents. I can tell you, it’s not trivial at all.
One of the big obstacles in this is simple: AI-written code is shit. It’s a terrible spaghetti. It makes it the perfect solution to launch new startups, build new MVPs and prototypes. But it doesn’t even get through the front door in the enterprise where hundreds of people need to be able to collaborate and maintain the same code.
Will it get better? Sure. But even if AI could suddenly write fantastic code, there’s another problem: higher levels of agency equals to lower levels of control.
This is a huge business risk for the enterprise that slows adoption even if the disruption is real. Even if AI development stopped to a complete halt tomorrow, it would take the world 10-15 years to catch up completely.
AI lacks common sense
VERDICT: So-so.
LLMs ability to reason and think has become this weird unicorn of the AI world last year. It’s basically the nerd version of astrology now. I wrote about it in this article:

A few notable things (sources in the article)
DeepMind found out that you can indeed scale LLMs ability to solve sequential problems by allowing them to generate “intermediate reasoning tokens”.
A month later Apple followed up with a paper proving that even if they are useful, LLMs don’t actually use symbolic logic.
LLMs can parrot reasoning very convincingly but it doesn’t reason.
However, this is not the full picture. Just because it’s not using logic, it doesn’t mean it cannot be useful. (We all know some people who also fall into this bucket.)
This research came up with a few interesting insights. It seems that the ability for LLMs to solve problems keeps growing when we allow them to generate more intermediate thinking tokens. This finding is similar to DeepMind’s finding from last year. This can be simple as “an internal monologue ruminating on the subject” or more complex like “recursively generate solution ideas and vet them against each other.”
Either way it’s clear: the smarter you want your model to be the more tokens you must generate per query. Thankfully since 2021 the cost of token generation has decreased by 10x every year.
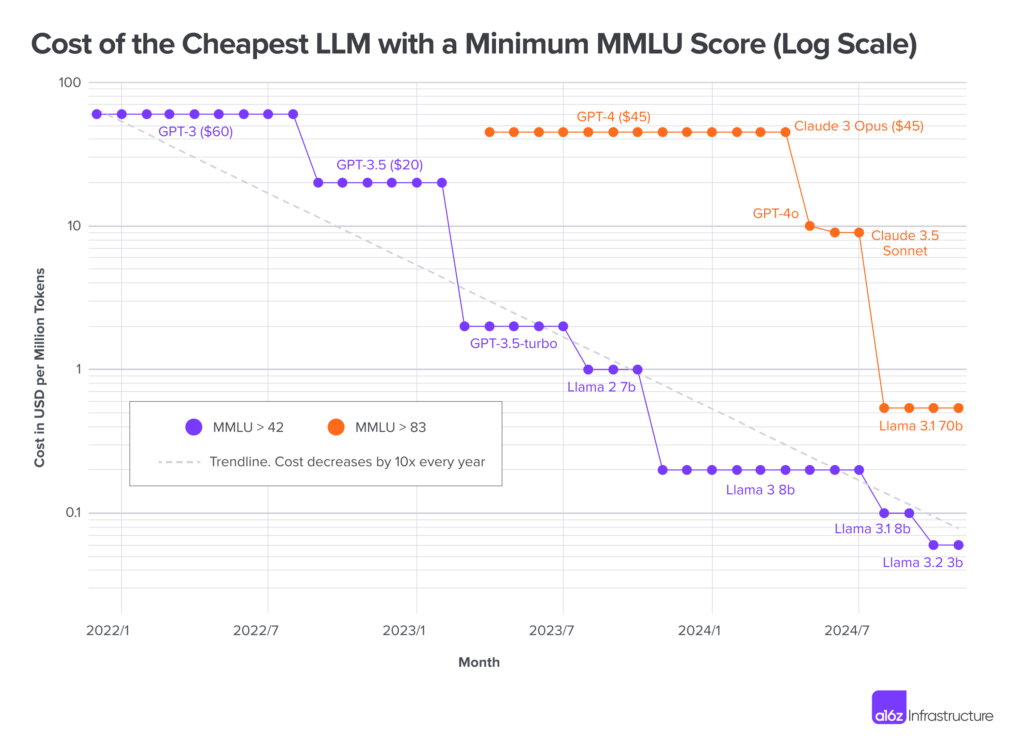
We don’t have the hardware
There is one thing that is still missing from the picture: generation speed.
I read somewhere that the average ChatGPT conversation is about 2000 tokens in total. What would the world look like when a simple prompt would generate a million reasoning tokens before answering? What would the world look like if this would happen in 0.1 seconds?
Token generation speed is a hard limit in real world use cases. You can make models more useful by allowing them to generate intermediate reasoning tokens at scale, but that slows the models down.
ChatGPT generate an average of 70 tokens per second.
Mistral’s Le Chat and Groq can do up to 1500 tokens per second.
I’ve seen Cerebras generate over 3000 tokens per second in some cases.
Let me explain to you why that’s important:
Let’s say you prompt GPT-4o and it responds in 1 second with a 50 word answer, but the answer is bad. It’s not what you want, hallucinates, etc.
Then you first prompt it to generate some thoughts about how to solve the problem. It outputs 700 tokens to you in 10 seconds. Then you prompt it to give you the answer (Typing takes you another 2 seconds and then you get a final response in 1 second). So to increase “intelligence” by an order of magnitude, you needed to 10x the time it needed to complete it.
Let’s say this still doesn’t work. Let’s say you need to generate 700,000 reasoning tokens. Today you can use Gemini for that (so it doesn’t lose out on context) which generates tokens a bit faster. So we’ll say 200 tokens per second which is roughly the speed of Gemini Flash 2.0.
This means the model would think for 3500 seconds. Then you prompt it again in 2 seconds and get a response in one, totaling in 3503 seconds. That’s almost an hour.
If we used Cerebras’ inference and achieved 3000 tokens per second (disregarding model differences) this task would be completed in 4 minutes. That’s still very far from the “real-time latency” limit of 400ms, but it’s at least an order of magnitude faster.
This is the hard limit currently. Token generation gets cheaper at an astonishing rate but tokens per second doesn’t improve as fast. Because of this simple reason, open agents that can solve anything are currently not viable.
We would need a model that can generate up to 1 million tokens in under 1 second at 1/10f of the cost of GPT-4o-mini to make it happen. If the trends continue, the cost won’t be a problem in 1-3 years. But the speed remains a big issue. Until this is solved, it doesn’t actually matter if models reason or not. It doesn’t matter is Gary Marcus is right on neuro-symbolic hybrids.
You can just try throwing more GPUs at inference to increase speed but at this scale of usage it’s not viable. This exchange on X is a great summary of what we’re looking at:
AI is eating the world
AI is gobbling up our computers and our data faster than we can manufacture new chips. There is no sign of this insatiable hunger receding anytime soon. Stargate’s $500B investment was soon met with the EU’s €200B pledge.
The problem is not that. The problem is that we have no idea what to do with it. This is a grand project for all of us, humans. Trying to make space in our world to this new kind of intelligence.
This is why the work of AI Architects is important.
This is why experimentation is important.
This is why going from use case to use case is important.
There are no standards for how to adopt AI in an organization.
Which part of your world is AI eating?
So maybe instead of waiting for the magic intelligence in the sky, we should look at how we can best utilize AI tools to actually help us create value (not slop). How to use narrow agents to solve our problems today instead of contemplating about the open agents of tomorrow.
For solopreneurs and small business owners, one approach to this is alfredOS.
I’ve been working on a self-hosted solution that provides a full set of software for small business owners that replaces over $1k/mo worth of SaaS subscriptions, with an embedded AI tool that connects to every single app via Model Context Protocol.
This allows you to chat with a model and basically run your entire business from a chat interface. You can still pre-order for $147 here. (This is one of payment, you’ll only need to pay server costs after this).
Really interesting article! Curious, is there a way to automate which LLM is selected to run a prompt based on what the prompt is asking and which LLM is best suited to complete the task?
AI is now better shit, but shit none the less.