
We're not feeling the AGI - Part 1
Times are changing in AI land

AGI is becoming a religion. I’m very bullish on AI, but bearish on us achieving AGI in the short term. This is a multi-part essay on why.
Prompt engineering is gone
Last November Microsoft published a paper on using prompt engineering and different prompting strategies to see if it can outperform fine-tuning. They called this prompting strategy “MedPrompt”.
The short answer was yes. Strategic prompting works better than fine-tuning.
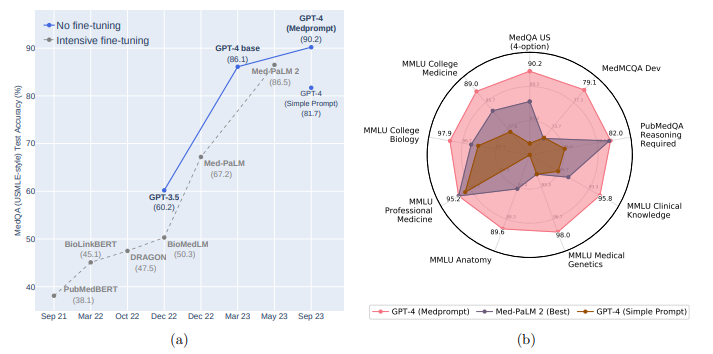
A year ago if you knew how to prompt well, you could unlock more value from a frontier model than a fine-tuned LLM.
Then o1-preview was released.
A follow up to the original MedPrompt paper was published only a few days ago. The findings were definitive.
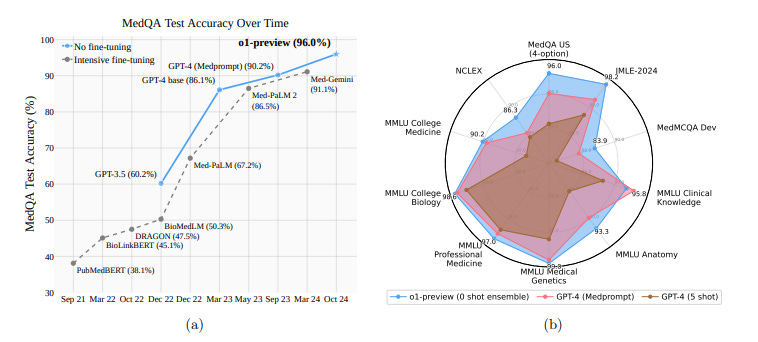
Medprompt is outperformed by o1-preview on 7 out of 9 tests.
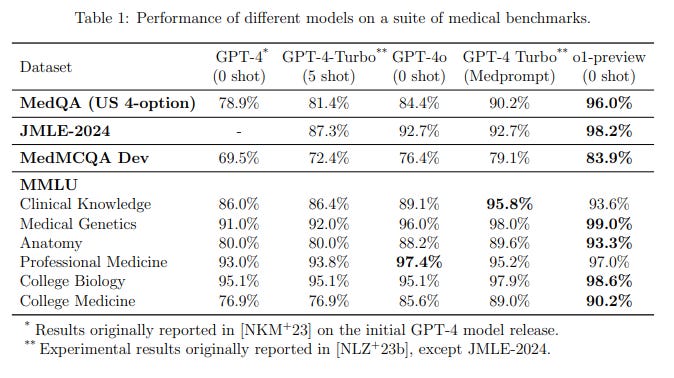
Unsurprisingly, Nori et al makes an observation that:
“Our findings (Figure 1 and 2) indicate that the o1-preview model outperforms GPT-4 augmented with Medprompt on the benchmarks studied and suggest a diminishing necessity for elaborate prompt-engineering techniques that were highly advantageous for earlier generations of LLMs.”
Prompt engineering is dead and o1 killed it.
Smarter than humans
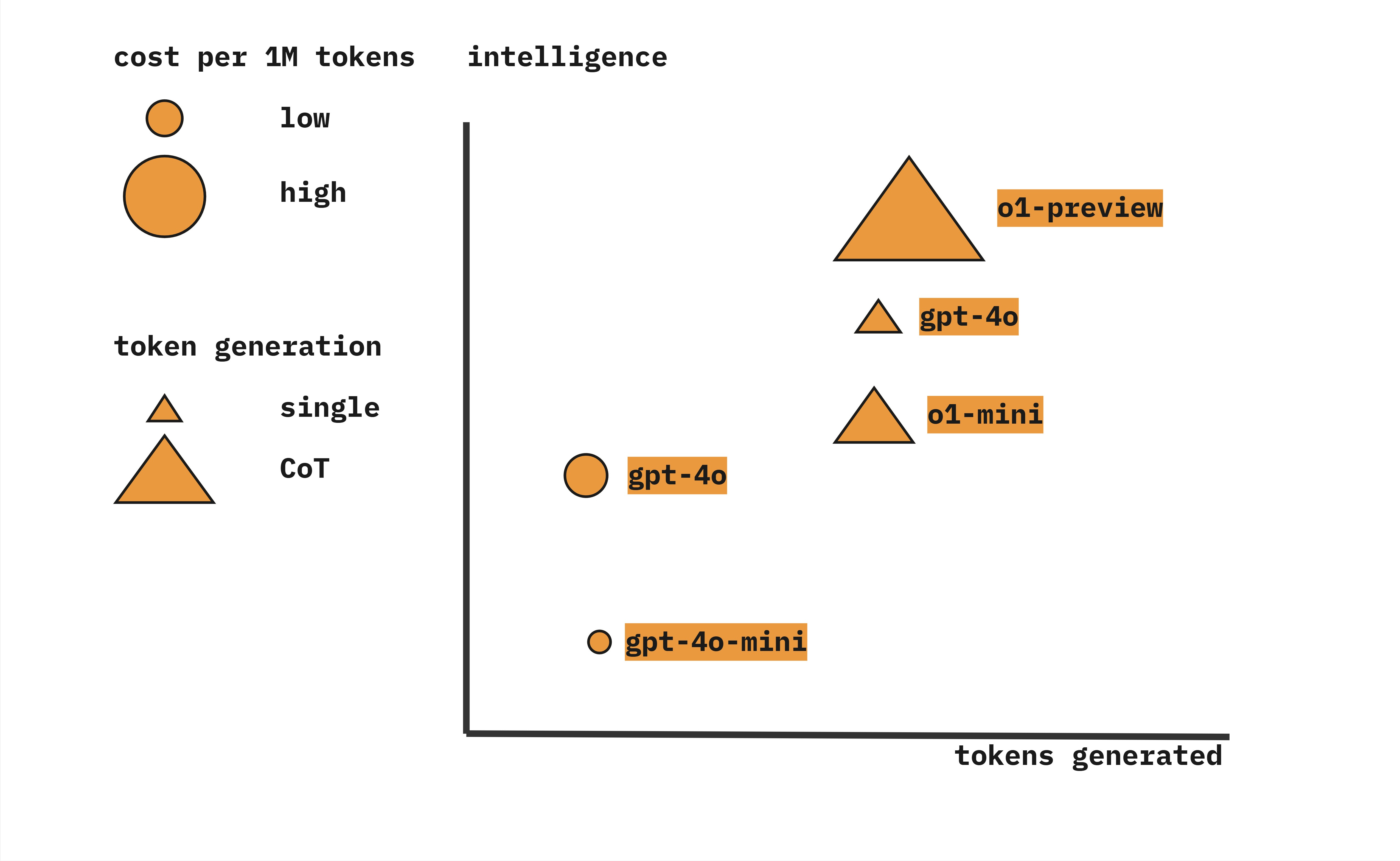
Maxim Lott, author of the Maximum Truth covered the capabilities of o1-preview brilliantly, but I’ll try to show it in one image.

Using o1 is not just easier as we saw earlier, but it is also superior to previous GPT models. Now that everyone is in R&D, we just got a brilliant new model that scales intelligence with compute.
Unfortunately, performance is not the only thing that scales with compute.
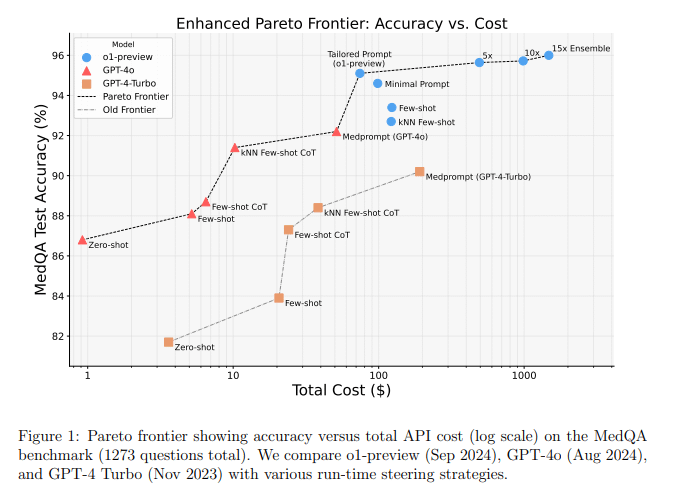
Note that the X-axis is a log scale. Being smart is expensive, even for computers.
As they observed:
“While o1-preview excels in terms of absolute accuracy, GPT-4o offers a well-balanced solution with strong performance at a lower cost.”
The question then becomes: can we somehow replicate o1’s superior architecture but at a lower cost using other models like GPT-4o in a way still doesn’t require prompt engineering from the user?
LLMs are simple. The more data you feed it, the more robust the model becomes at generic tasks by mimicking patterns in its training data.
ChatGPT became so good at it, it broke the Turing test over a year ago.
But as we saw in Lott’s IQ chart, most frontier models lag behind the median human intelligence. But o1 is different. It’s smarter than most humans.
Inference-based intelligence
A few weeks ago a paper from Stanford, TTI, and Google was published on solving serial problems using Chain of Thought. This paper found mathematical proof that Chain of Thought reasoning doesn’t have a limit of performance when scaling inference.
As Denny Zhou from DeepMind, one of the authors of the paper said it was possible, “provided they are allowed to generate as many intermediate reasoning tokens as needed.“
So I can use o1 which is smarter because it generates a LOT of reasoning tokens but is expensive. Maybe I can use GPT-4o to generate reasoning tokens for less?
Given that o1-preview costs ~6x more per million tokens than GPT-4o, if I found a way it’d be worth it.
Based on my work — which I document extensively in our free Discord community (click here to join if you haven’t yet) — I’ve drafted a chart that is based on my experience. It’s empirical and for illustration purposes only.
This has only one caveat: a GPT-4o sequence must solve a serial problem. In other words, it has to work as a narrow agent, instead of an open agent.
This is a major difference between our CoT use of GPT-4o versus o1’s alleged capabilities. The latter is a general-purpose reasoning model that is working efficiently on open-ended problems.
If o1 uses reasoning when it generates reasoning tokens, then that’s a big fucking leap from GPT-4o. Unfortunately, as we learned from the Apple paper published in October, LLMs don’t actually reason, including o1.
The 6x price premium for using o1 over GPT-4o sequences is not justified. Narrow agents are more useful for real-world use cases than open agents, because:
You have more control over how the “reasoning tokens” are generated.
They’re cheap to run.
But they’re not AGI.
If AGI will neither be built from better training nor sequential inference, then what?
AGI needs cognitive architecture
It seems like there’s a missing link in the architecture of AI agents that prevents us from building AGI.
An article on Sequoia Capital’s blog was published on October 9th that claimed that in this next wave of AI, cognitive architecture will be the moat. Multi-agent networks all powered by custom architecture will solve real-life problems, birthing a new wave of startups.
Multi-agent AI can indeed tackle complexities LLMs can’t. To go deep, read this.
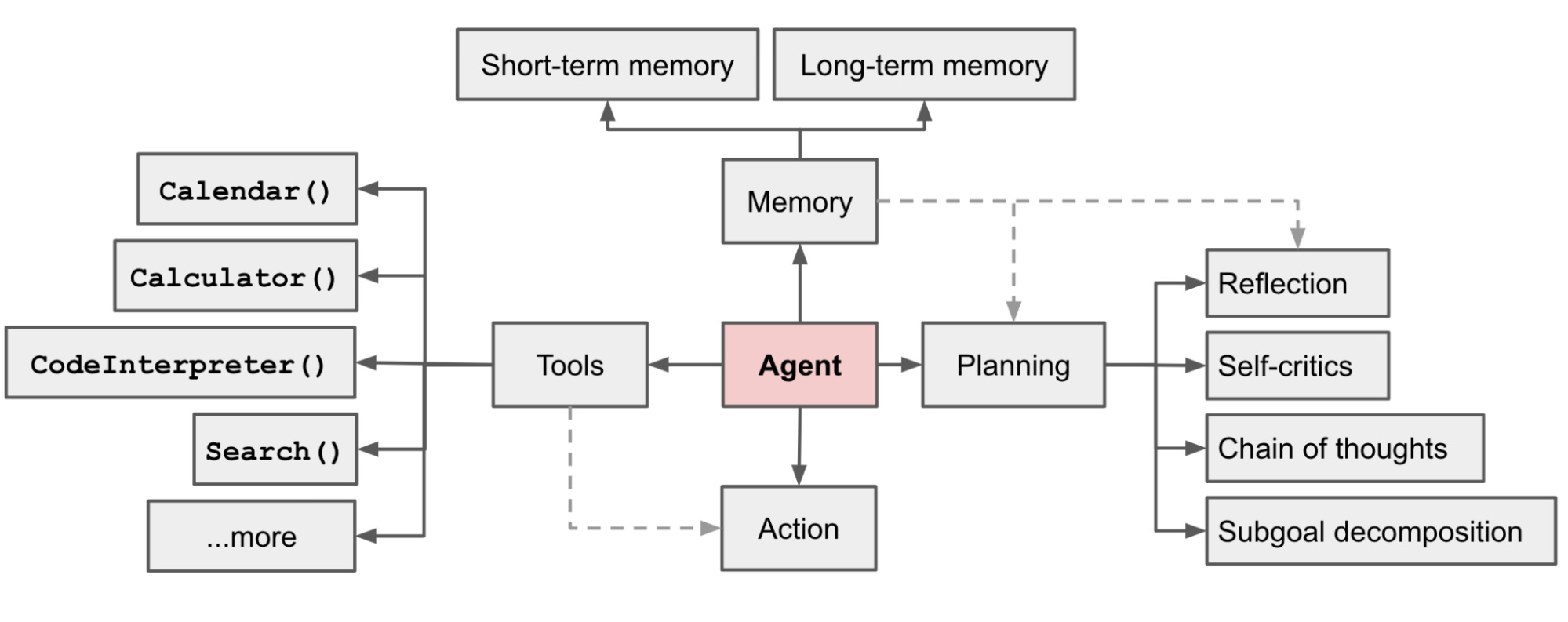
Hm. Looks like you’re achieving System 2 thinking at an architecture level.
Let’s see what we have here:
Memory
Tools
Reasoning
Memory
We thought RAG would solve hallucinations once and for all, but it doesn’t work. Then Microsoft tried to solve this problem with GraphRAG adding knowledge graphs to embeddings.

Running GraphRAG faces a similar problem than using o1-preview. It’s fucking expensive.
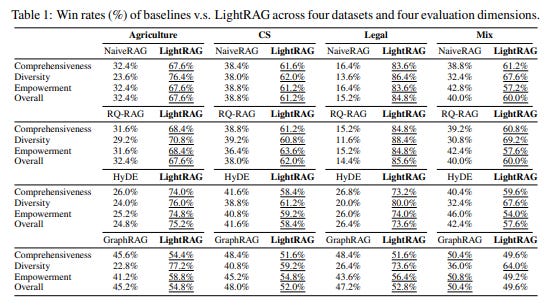
A good alternative came from the open source community called LightRAG. It’s cheap to run and outperforms GraphRAG in a bunch of cases.
Tools
Claude can now use your computer. OpenAI is jumping on board with rumors of launching “Operator” very soon.
But again, we face the same issue: price.
I was testing Computer Use for about half an hour via Replit and it generated almost half a million tokens in the process with Claude 3.5 Sonnet.
If I used this for my butler project Alfred I’d probably generate 5-7 million tokens per day, costing me $4-600 per month to run this.
It’s hard to justify such a cost even if it completed all tasks successfully. But it didn’t.
It loops itself into random tasks, racking up API costs while randomly failing to complete tasks.
Then it hit me.
I’ve seen this before.
Reasoning
The purpose of having a cognitive architecture that brute forces LLMs to think logically is to gain autonomy. But agents cannot reason and when given autonomy they break down.
The concept of autonomous agents performing tasks on behalf of humans is not new.
Here’s a footage of me testing a rudimentary AI agent using I built with AutoGPT and the ElevenLabs API 19 months ago, back in April 2023.
Even Sam Altman admitted in 2023 during the Hawking Fellowship Award that “we need another breakthrough.”
It’s probably fair to say that he was convinced that Orion/Strawberry/Q* or whatever the fuck they call this thing now would be that breakthrough.
It’s becoming clear that it’s not. AI development is slowing down. Companies are selling old broken tech as new to maintain a sense of momentum.
But we’re just not feeling the AGI.
And that’s a good thing.
to be continued…
Great article! One small quibble: the profanity might be normal in your friend circles, but it's not normalized in much of the world. It adds nothing to your text and will be off-putting to many people. Cheers!