
Creating cognitive workflows
LLMs hallucinating is a good sign of overwhelm. Try this instead.

This post is the follow up to my post yesterday on temperature and LLM creativity. If you haven’t read it, it’s okay, this article works as a standalone too.
However I still think you should. It’s a good piece.

On Friday I got a question from one of the community members in the Lumberjack Discord, I’ll paste it here. He is not alone, I see this issue often.
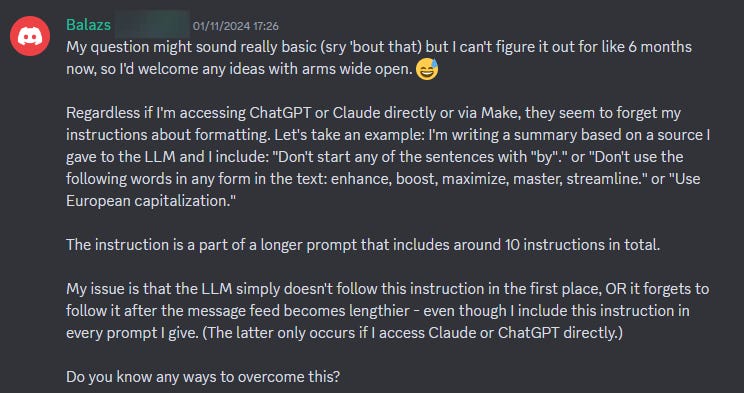
My immediate intuition was that Balazs was overwhelming the model. He gives too much information in the prompt and the model can’t keep up.
I asked him to give me the prompt he was using.
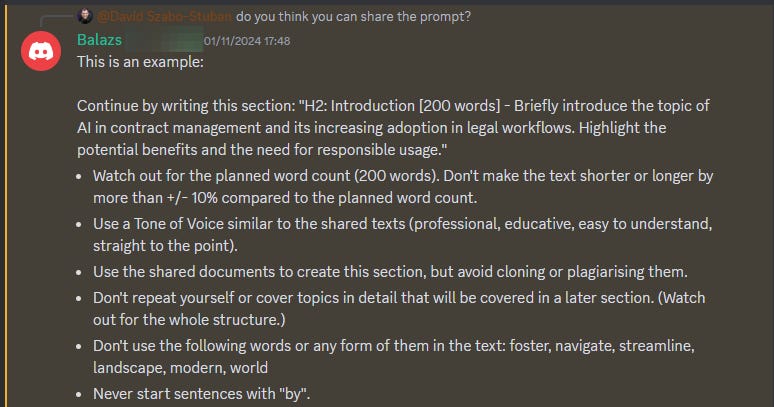
A year ago I would’ve told him to rewrite the prompt using prompt engineering methods, better wording, etc.
But as I gain more experience in using and building with LLMs, while the tech itself is evolving, my understanding has changed.
Yes the prompt is a problem. But the solution is not another, better, more structured prompt. The solution is a different approach.
I experience this a lot when I take calls with people. They start telling me all the intricate details of their problems and I need to stop them at some point because I’m getting so much information, I cannot process them.
So yeah, I can totally understand ChatGPT dropping the ball when people send it a wall of text.
Instead of just prompting, I suggested creating some kind of cognitive workflow.
Cognitive Workflows
In the case of Balazs, the cognitive workflow looked like this:
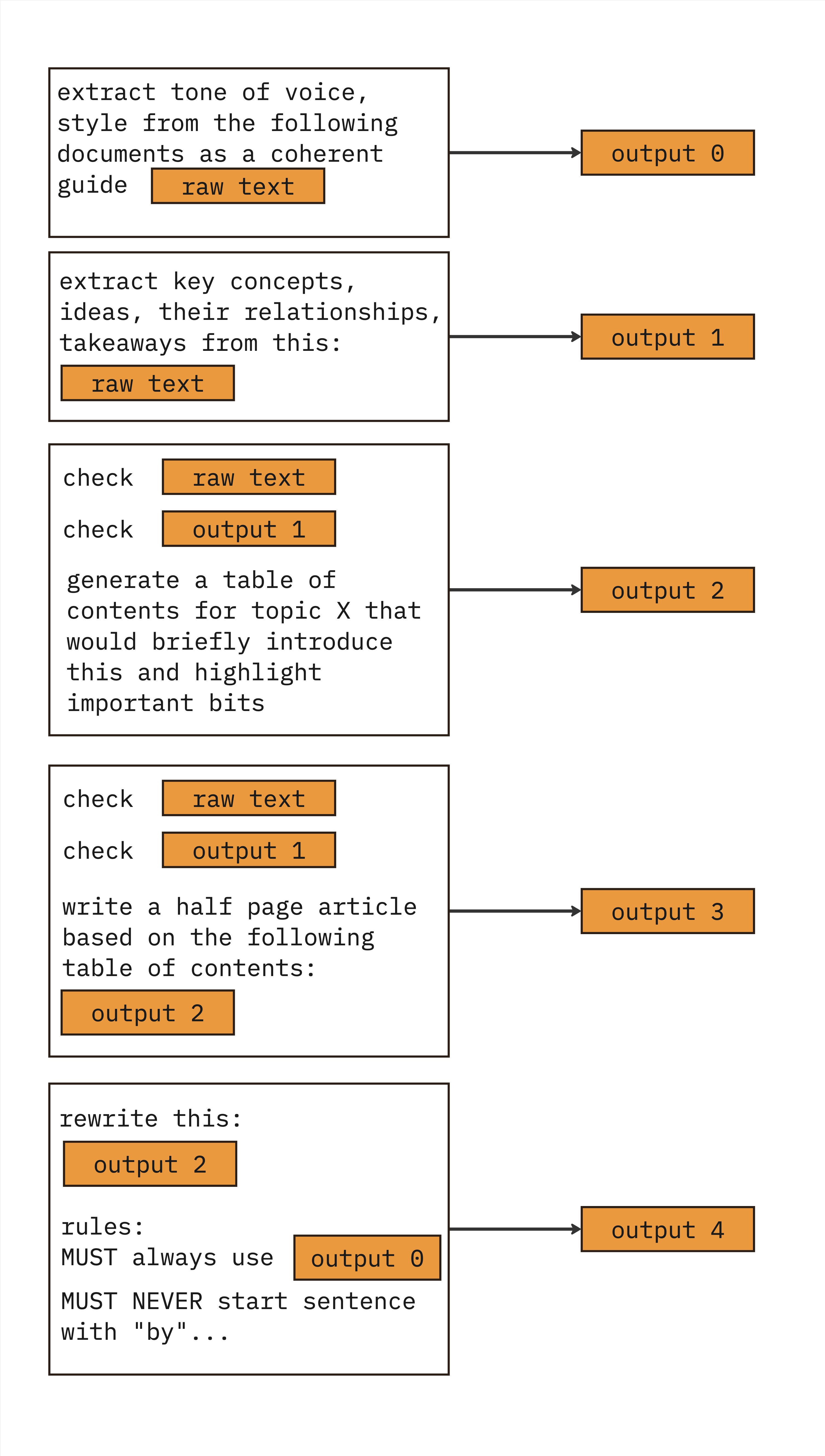
Just to be clear: A white rectangle with black borders is one prompt. Here you send 5 prompts and generate 5 responses.
You could argue that I hardcoded a Chain of Thought sequence and you would be right. Chain of Thought works. Thanks to the DeepMind et al, we know that Chain of Thought can unlock LLMs ability solve inherently more complex problems. Here’s the paper: Chain of Thought Empowers Transformers to Solve Inherently Serial Problems

However we also know that LLMs don’t actually reason, from this article:
GSM-Symbolic: Understanding the LImitations of Mathematical Reasoning in Large Language Models

If you’re interested in the whole “AI reasoning” topic, Jurgen Gravestein wrote a phenomenal article about this:

I also covered this topic recently:

Hardcoded reasoning
While o1 and other reasoning models are using a general-purpose, dynamic way of creating Chain of Thought sequences, my cognitive workflow example is a hardcoded one.
Reasoning is done by me (when I’m designing the workflow) and the thinking is done by the LLM as it goes through the series of completions. For smaller, simpler tasks —like in the case of Balazs — we don’t actually need the model to reason.
This is what a cognitive workflow is. A predetermined step of instructions that the LLM-based workflow goes through, progressively using more of their own data as opposed to the source data.
This unlocks greater control over LLM parameters. One of the most important is temperature. During this workflow, when I’m asking the model to rewrite or reformat existing text, adhering to formatting rules I set, I don’t want the model to provide diverse responses.
How does it look like?
I design a lot of cognitive workflows for my clients. They usually deal with a huge amount of unstructured raw text, some entity extraction (key ideas, concepts, their relationship, etc) and then some repurposing.
This can be simple, like this:
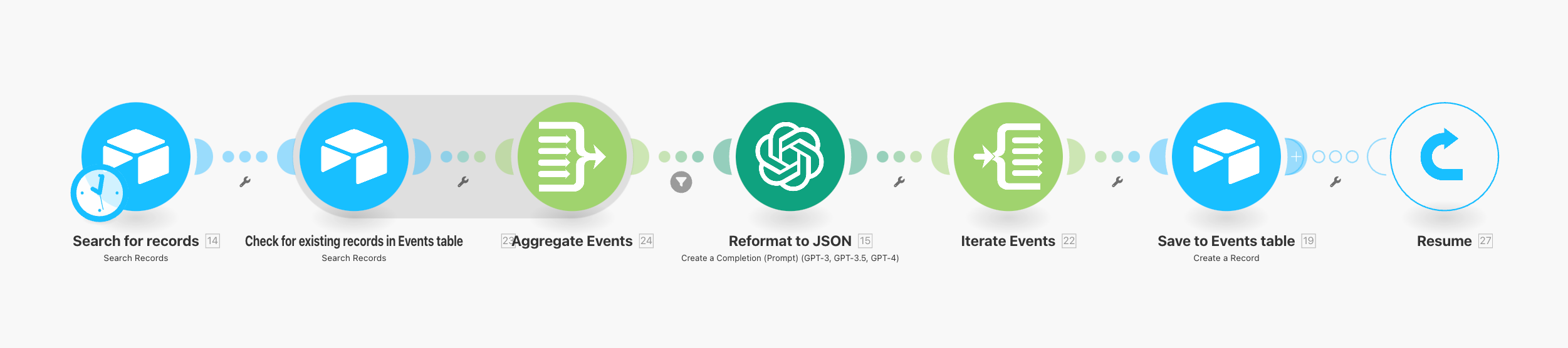
This is part of the Content Generation Machine I’m building for No BS Agencies. You can read more about that here :

This specific workflow takes the raw list of events with timestamps that was exported from Circle as a string and uses GPT 4o-mini to reformat it to a valid JSON and populate a new table in Airtable.
This might sound simple, but this kind of data cleaning is basically 90% of the job when building AI agents — and more importantly, this has nothing to do with agentic AI at all.
Cognitive workflows can be more complicated too, like this:

In this workflow I’m taking raw audio recordings of site visits for a construction company. I’m using AssemblyAI to transcribe the audio and then through several prompt completions I process the information. I query the database of the company’s tech stack to get the IDs of current jobs and their supervisors and attempt to match them with the transcript. I also generate some intermediate tokens that allow me to categorize the action steps in a way that is synced with the company’s project management system.
Usually when you see multiple OpenAI (or other) modules being called in a linear sequence in my work, that means an advanced cognitive workflow is happening, with OpenAI modules referencing each other.
If I would want to build a solution for the problem Balazs asked me about, the end result would also look like something like this. (The black and red dots tell you that I didn’t actually build this out, Balazs said he wanted to tackle this himself.

To code or to no-code
That is the question. Well, it’s not really a question. For designing cognitive workflows, I think Make is uniquely superior to most no-code tools. Another option would be Flowise (here’s the GitHub repo), but I haven’t yet tried it.
Main reason is that you can just duct tape together a simple way to treat Google Doc as a data lake. I can just open a new GDoc, paste all the raw text in that I want to deal with and call the Doc from the Make scenario. Then I can just plug in whatever number of completions I want to generate.
I can customize LLM parameters, response formats, temperature, model use and some other stuff with a single click.
Of course if you need to handle a large amount of data, once you’re done with the cognitive workflow prototype, chances are you’ll be better off building an app for said workflow, host it somewhere like Vercel or Heroku and run it that way. Otherwise you’d end up spending all your precious Make operations on manipulating and sending JSONs.
With CursorAI you can built an app that does that for you easily, without having to code at all. But more on that next time.
Until then, join the Lumberjack Discord. We have over 200 300 members now and growing like crazy!