
Temperature in LLMs is not creativity
The key to getting rid of hallucinations in AI automations

Temperature is often called the "creativity parameter" in LLMs. Higher temperature results in more diversity in responses which sometimes lead to interesting results. But it has nothing to do with creativity.
Softmax
Don't forget that an LLM is basically a very sophisticated autocomplete. So as an example, let's say:Lumberjacks make a living by cutting ________ Then we send this sentence to the model as a prompt to generate a completion. Before we would get the response, the model calculates prediction values to different words and assigns a value to them, like this:
Token Logit
wood (50)
logs (48)
trees (47)
branches (45)
stumps (44)
bark (43)
leaves (42)You'll notice that these don't add up to 100. That's because it's not a percentage, but a raw computed value. In order to normalize it (so they add up to 100) , LLMs use a function called softmax. This function transforms these values onto a probability distribution based on how they relate to each other.
In other words, softmax makes it so, that it doesn't matter what the actual values are, what matters is how big the gaps are between them. Now let's run these values through softmax:
import numpy as np
import pandas as pd
# Tokens and their corresponding logits based on the updated values
tokens = ["wood", "logs", "trees", "branches", "stumps", "bark", "leaves"]
logits = np.array([50, 48, 47, 45, 44, 43, 42])
# Softmax function to convert logits to probabilities
def softmax(x):
exp_x = np.exp(x - np.max(x)) # for numerical stability
return exp_x / exp_x.sum()
# Calculate probabilities
probabilities = softmax(logits)
# Create a DataFrame to display results
df = pd.DataFrame({"Token": tokens, "Logit": logits, "Probability": probabilities})
df
Once you run this through this script, you get the actual probability:
wood: 83.64%
logs: 11.32%
trees: 4.16%
branches: 0.56%
stumps: 0.21%
bark: 0.08%
leaves: 0.03%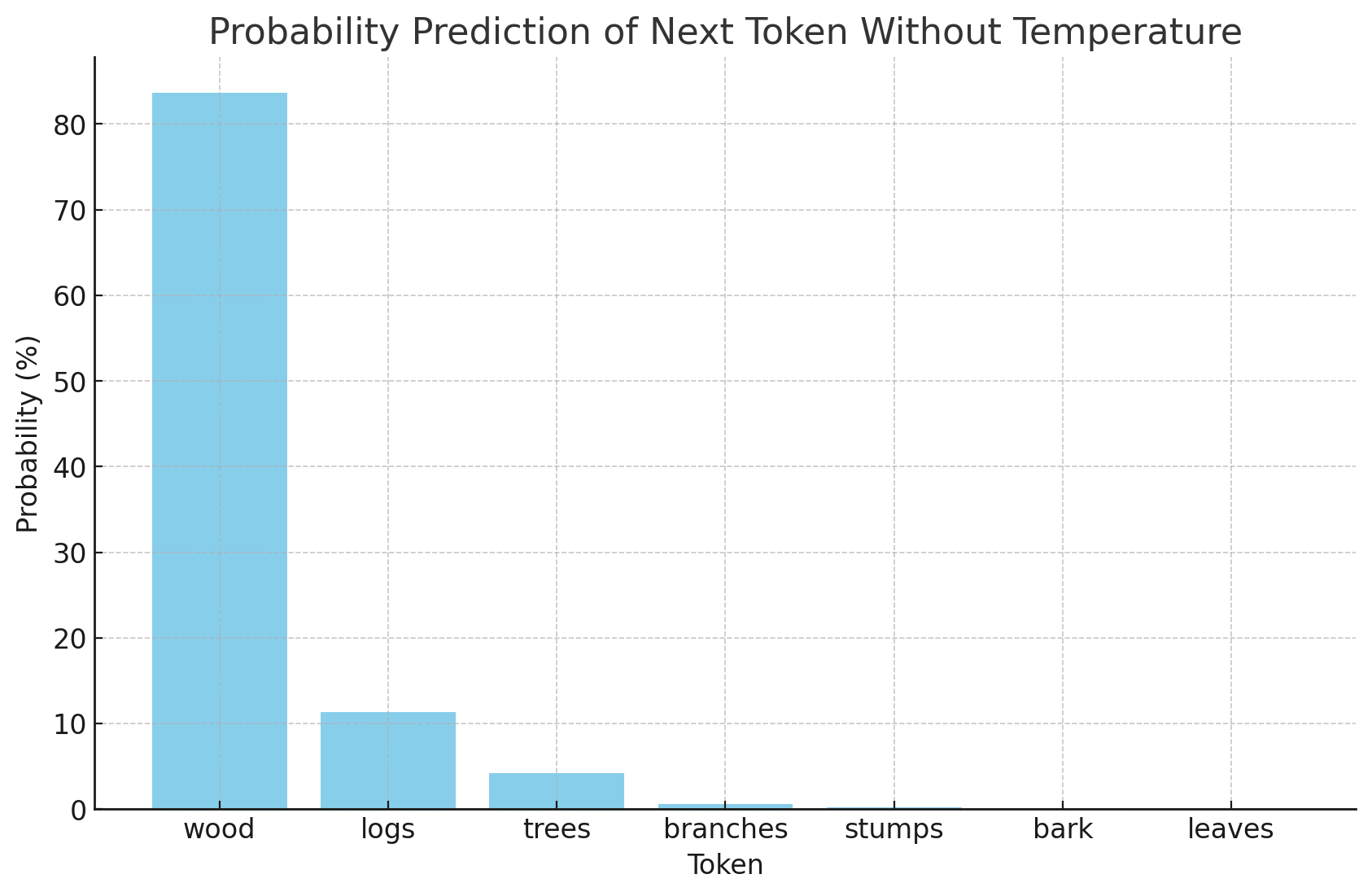
As you can see, wood dominates but logs have some chance of winning the prediction too, with trees being the third. It kind of makes sense.
Temperature
This was without temperature. Now let's see what happens if we introduce temperature into our softmax formula. I won't go into the mathematics, but here's what happens. Temperature influences how confident the model is in the highest probability token. If temperature is 1, the probabilities are as above. However, when we reduce temperature to 0.5, here's what happens:
wood: 97.96%
logs: 1.79%
trees: 0.24%
branches: 0.00%
stumps: 0.00%
bark: 0.00%
leaves: 0.00%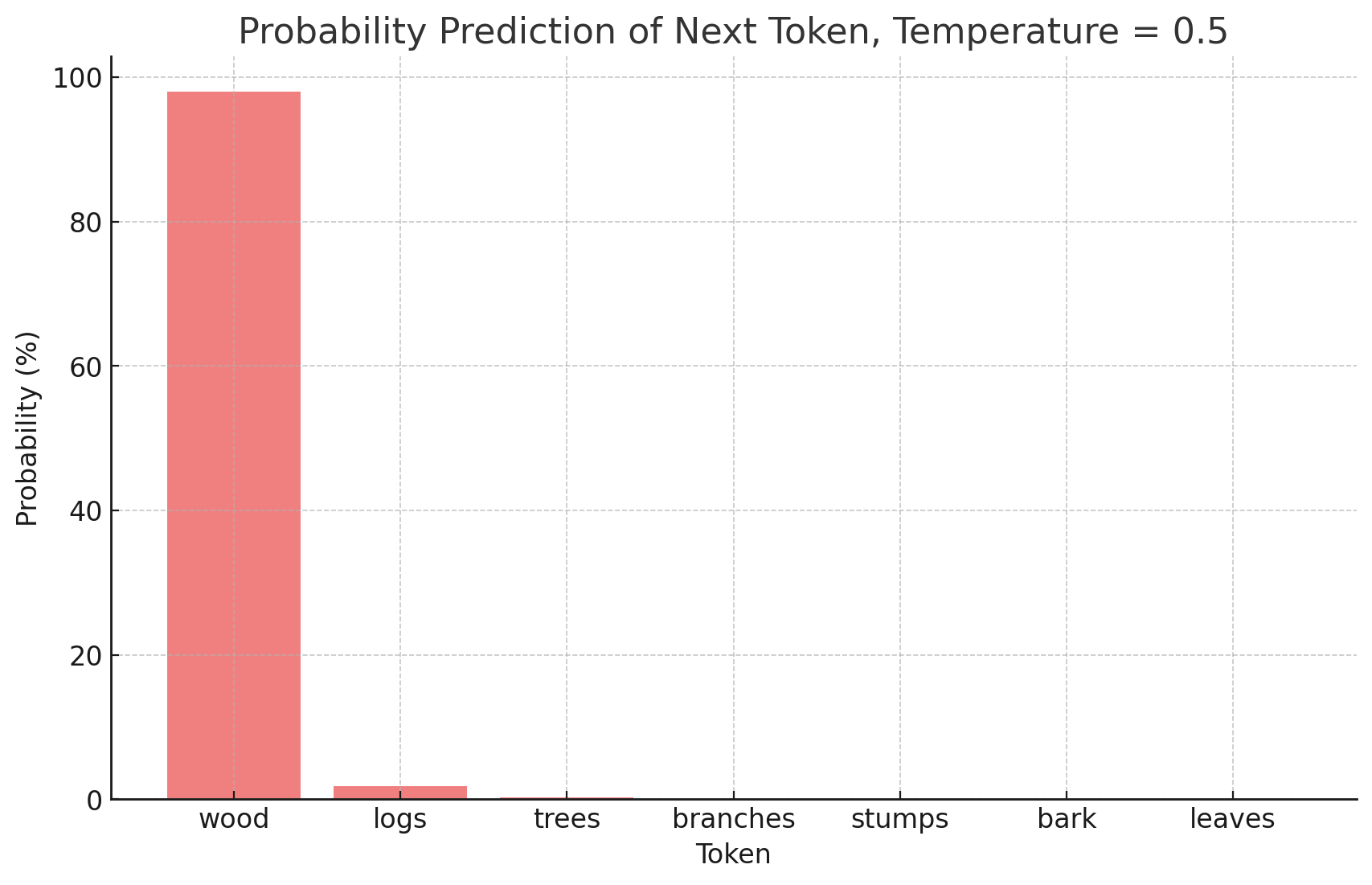
The model became more confident that wood should be the next token. There's still some variability in the responses, but a lot less. Now let's reduce temperature to 0:
wood: 100%
logs: 0%
trees: 0%
branches: 0%
stumps: 0%
bark: 0%
leaves: 0%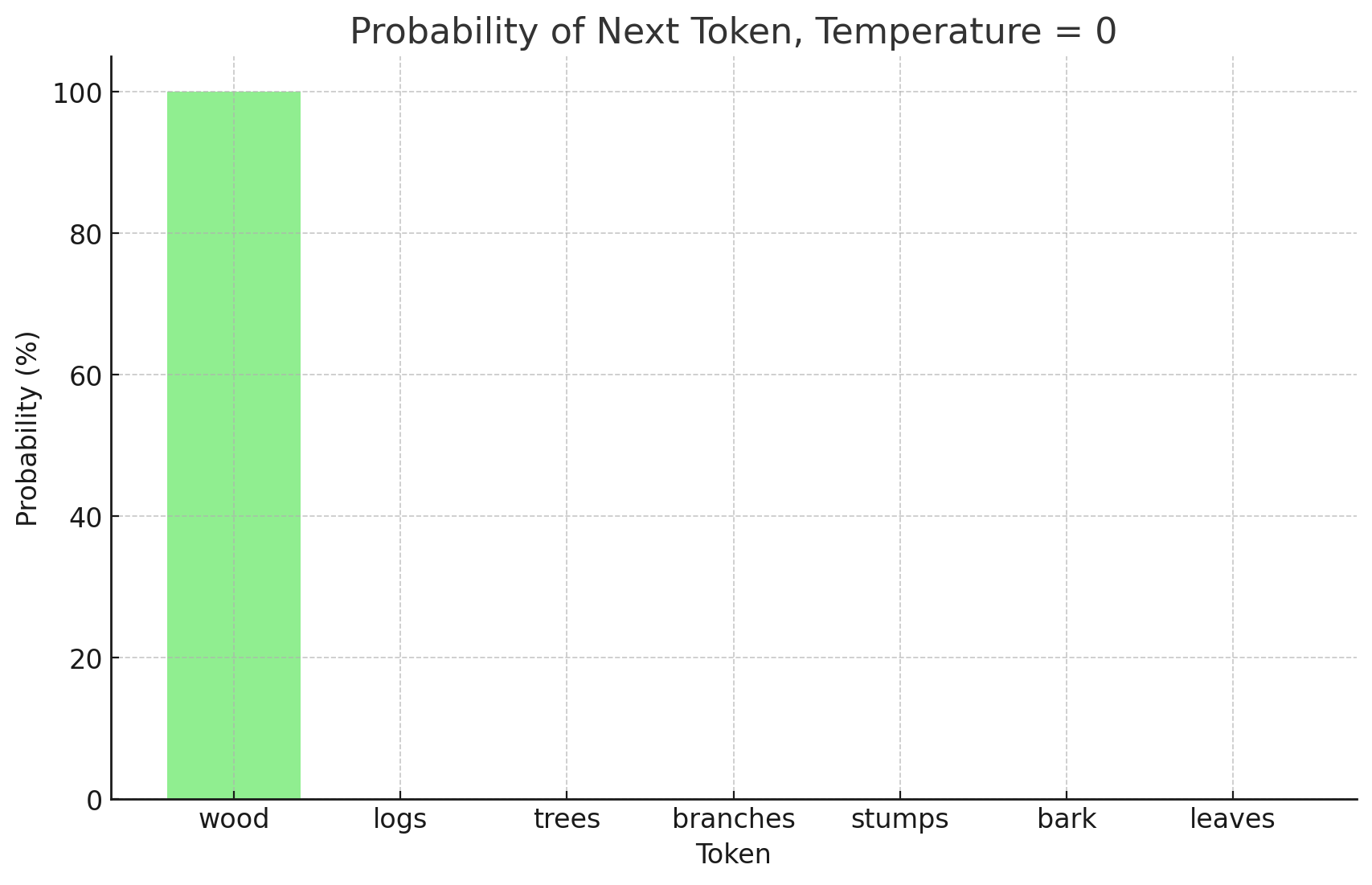
Why this matters
Comparing all three you’ll see that as you reduce temperature, the model becomes more confident in its first choice.
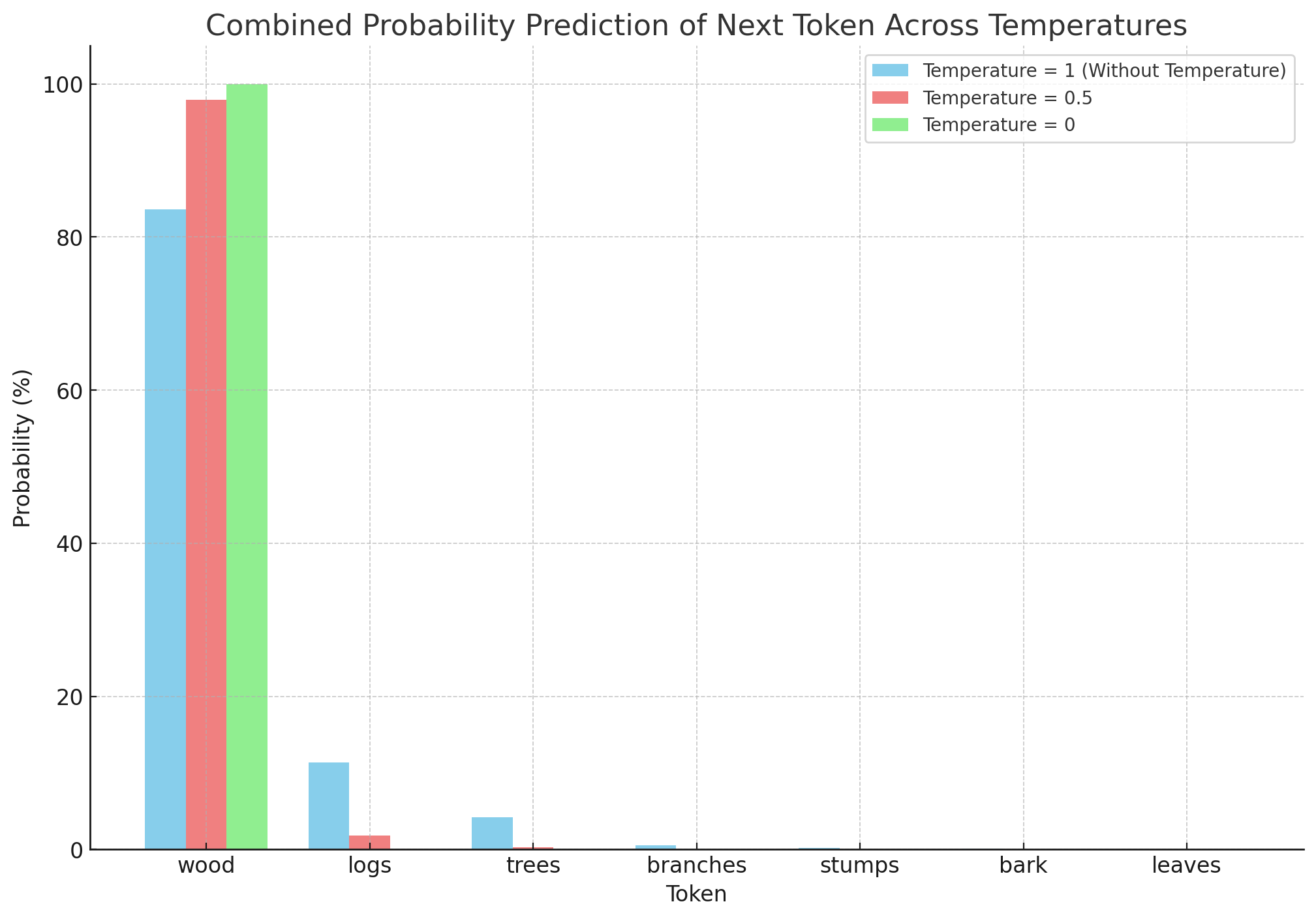
Once it reaches 0 temperature, you see no hesitation. This basically means that the same prompt will always return the same response. So if you keep testing what prompt you should use in your AI agent for a specific task, once you found it with 0 temperature, you can be 100% confident it'll return the same thing consistently.
The model is 100% confident too after all.
For automated or semi-automated workflows you want consistency as a default and creativity when needed. You don’t have to worry about double checking everything all the time.
This is why I always aim for using models with 0 temperature when building automations. This practically turns the LLM into a deterministic system where you'll always get consistent and reliable responses.
However this creates a new problem: sometimes you want variability in the responses. Sometimes you want to unlock the randomness in responses for more diverse output.
This is also why I like to break down my prompts into multiple completions. That way I can control which parts of the task should have creativity or diversity and which should just robotically parrot the same kind of response all the time.
Real life application
Most of the questions I get are similar to the one below, that can be resolved by this easily. Below is an example from one of the community members on the Lumberjack Discord.
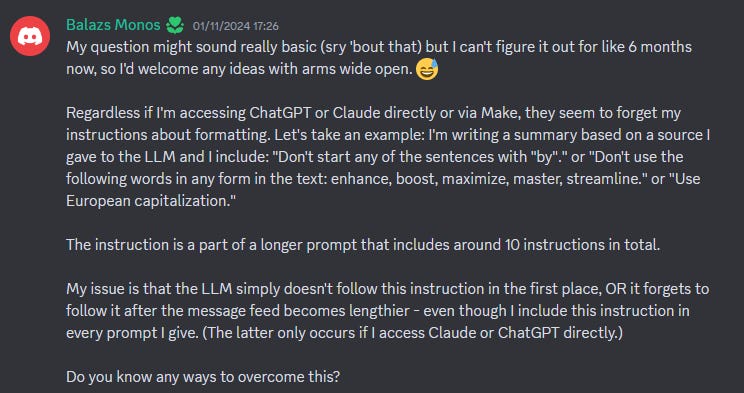
I’m trying to write shorter emails and posts so check back in tomorrow for my answer.
If you don’t want to wait, join our Discord server here, you’ll find the conversation in the general chat.
It’s fully free and open, we’re growing fast with almost 200 over 300 members now.
Great piece, love the technical insights! I’m about to publish an article myself about hallucinations, too.