
We are not feeling the AGI - Part 2
The world is not ready for o3 yet.

TL;DR: To reach AGI we need it to be intelligent, cheap, and have real-world utility. While o3 is the most intelligent model yet, we still have none of these criteria. Humans are slower to adopt than how fast new models are released. The world is not ready for o3 yet.
Disclaimer: I wanted to publish this post in January. The world will not miss another analysis of the new o3 model, but here I am. This is Part 2 of my "We are not feeling the AGI" post and today I will make three main arguments. These three arguments are the basis of my expectations for 2025.
In 2019 François Chollet proposed a new definition for AGI in his paper "On the Measure of Intelligence":
The intelligence of a system is a measure of its skill-acquisition efficiency over a scope of tasks, with respect to priors, experience, and generalization difficulty.
He is now working on creating a new set of challenges that will humble OpenAI’s new model o3. If you’ve seen the ARC-AGI tasks, you might wonder what’s so hard in them. They look like this:

This is because a good proxy for measuring intelligence is to create puzzles that are easy for humans to do but hard for AI to do. Moravec's paradox explains that what's hard for humans is easy for AI and vice versa. So if what's easy for humans becomes easy for AI too, we will have created universal intelligence.
But this also needs to be available and valuable.
Availability means affordability, which means cheap compute. Value means its application is ubiquitous to the majority of humans. Otherwise, you don't have universal intelligence, you just have a tech demo.
To build AGI, we need to fulfill three criteria: Intelligence, utility, and availability.
Even if we accept o3 as being superior in intelligence as of today, we're still missing two other components.
Intelligence is expensive
Comparing costs of gpt-4o, gpt-4o-mini, o1, o1-mini, o3, o3-mini we see a clear trend. Costs grow exponentially. This is because the core of reasoning models is a chain of thought: a model prompting itself over and over again.
This means that the intelligence is now not a function of model training but a function of inference steps. Even if the cost per token remains the same, each step of a chain of thought multiplies the number of tokens generated. This is what we call "intermediate reasoning tokens."
I covered this in more detail here:

The model doesn't just simply prompt itself over and over again but creates a conversation between different instances. This means that with a single prompt, you generate exponentially more tokens, driving up costs.
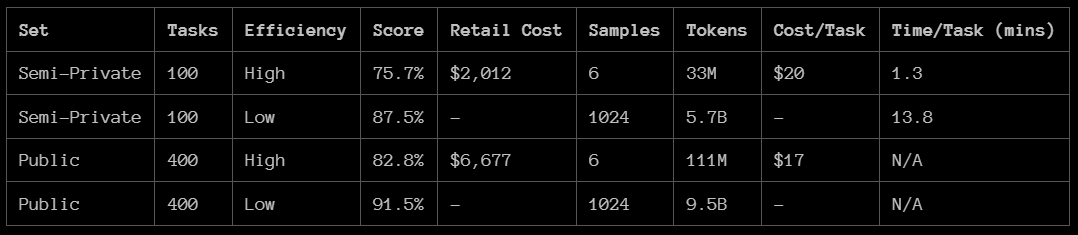
This seems true when we look at the ARC-AGI puzzle data: low compute used 33M tokens while high compute used 5.7B tokens. While low compute generated a $20 per task cost, if the cost per token is the same, that would mean $3455 per task.
The real breakthrough are the mini models
OpenAI's main business strategy is following a classic Silicon Valley playbook:
Solve a hard problem by throwing money at it.
Throw even more money at it to win faster.
Then figure out how to make it cheap.
In OpenAI’s case this means:
Keep throwing money at compute to keep solving harder problems.
Hope there’s no wall so once we scale up enough, we'll get to a very expensive AGI.
Then the next problem will be compute, so work on infra (mini models) to make them affordable.
Keep the market on their toes by announcing prematurely (beating Google is a good way to keep investor money flowing).
In a sense there were only 3 meaningful announcements out of these 12 days:
ChatGPT Pro
price reductions via API (infra play)
announcing o3 (market play)
This is why I think that the mini models are the truly groundbreaking stuff OpenAI publishes.
They're playing the infrastructure game.
For simple tasks like restructuring text into JSON, using gpt-4o-mini is already practically free.
With the consistent release of mini models, I see a clear message to the market:
We don't only know how to make better models, but we're also good at making them cheaper.
This is a clear nod to Google, which seemingly bleeds capital to catch up to OpenAI. Their new reasoning model called "Thinking Mode" has a limit of 1500 responses per day. That's more than generous compared to 50 per week for o1. But somebody has to foot the bill.

But let’s put the money problem aside for a second. Let’s just assume that these models will become cheaper over time (as they have in the past).
There’s a bigger problem at play: decontextualization.
Intelligence is incomplete without context
Intelligence is not enough.
You also need context to create economic value.
From the above, we can see that even if we accept how vastly, amazingly intelligent o3 is, using this for co-intelligence would be incredibly expensive.
I use ChatGPT for about 2 hours per day constantly. During that time I solve about 10 tasks for my work.
This level of task completion is about on par with using high compute o3 based on the ARC-AGI puzzle where it took o3 13.8 minutes to complete one task, assuming ARC-AGI tasks and my everyday tasks are interchangeable (which they are not, but more on that later).
So this means I'd need to pay about $35k per day to have o3 as my co-intelligence. I know some people who would easily pay this amount without hesitation. 99.99% of humanity cannot.
It's easy to make the argument that "o3 solves PhD level tasks at $20 - $3500 per task cost, so writing my newsletter should be infinitely simpler."
That's the same bias that comes from thinking ARC-AGI tasks are interchangeable with everyday life tasks.
ARC-AGI is brilliantly designed to measure a system’s capacity for adaptive, test-time reasoning. However, by design, it strips away social context, domain knowledge, and open-endedness.
Suchman (Plans and Situated Actions, 1987) proved that humans operate in social environments where tasks are reshaped by constant renegotiation—something you can’t measure with a colorful grid puzzle.
Beating puzzles doesn't mean AI can immediately replace Karen in Accounting or Steve in Tech Support. That’s because Karen and Steve do big, messy workflows that require multi-step processes, quick judgment calls, hallway chats, and Slack clarifications.
In order to do that Karen and Steve need to be really good at managing these processes. Nonaka & Takeuchi (1995) highlight tacit knowledge—the unspoken, intangible expertise that makes someone good at their job.
Puzzle solvers don’t do coffee runs or chat with teammates to refine business requirements.
AI doesn’t have tacit knowledge.
Puzzles are not everyday work
I spend most of my days building real business workflows using Make, n8n, and other tools. These require branching logic, iteration, subroutines, and domain-specific data. Building them also requires building consensus among humans and managing a very open-ended, ambiguous process.
A single “task” can contain 20 micro-decisions and 5 references to external stakeholders.
This is why I'm certain that most “entry-level” tasks are still more complex than these puzzle-based “tasks”. That’s why direct cost comparisons between puzzle tasks and daily work remain an oversimplification—frankly, a fantasy.
A few weeks ago I published my guide on building AI agents with no-code tools.

In this post, I introduced my own framework for creating real business workflows. This taxonomy shows how high-level “agent” systems could, in theory, navigate real business complexity.
But each additional step—storing data, retrieving knowledge, following up with managers—multiplies the cost. The cheap illusions of “fast LLM responses” vanish once you require genuine “System 2” orchestration (like multi-agent reasoning and tool usage) at scale.
Using these platforms, you quickly see how tasks morph into nested loops, feedback checks, scheduling quirks, and domain constraints. The puzzle is 1% of the final workflow—maybe less.
Every step in a multi-agent conversation or retrieval pipeline chews through tokens, which in turn chews through dollars.
Not because it's so hard to solve a problem but because context is needed. By definition, AI lacks tacit knowledge, so it needs to acquire it.
Without contextualization, many AI demos are precisely that—demos of “look how we solved puzzle X.” The moment you embed it in a real process with real integration, the complexity (and cost) blow up. It’s a showcase, not a scalable workforce.
Watch the 12 days of OpenAI videos and tell me I’m wrong.
Intelligence is not inherently valuable.
OpenAI's other 9 announcements sent another message:
“We have no idea how to make good use of this technology at the moment.”
This is not unique to machine learning. Ironically, humans are struggling with this too.
In his book Hive Mind, Garrett Jones argues that IQ accounts for only about 10% of the variance in personal income.
In other words, if higher intelligence determined higher wealth, we'd see a major overlap between the Mensa member directory and the Forbes Top 100 list.
But we don't.
So if just being wickedly smart is not enough to be economically valuable, why do we expect the same from AI?
While AI development doesn't seem to be hitting a wall or even slowing down, there is definitely a deceleration happening right now: we're slower to adopt new technology.
The world is in this weird state where we're not really fazed by the phenomenal results of ARC-AGI as much as we were with GPT-4 last March. The hype is somewhat wearing down because the majority of the world still believes that LLMs are at the level of GPT-3.5.
Most businesses are oblivious to even the most basic AI-powered workflows. This is a field that's really difficult with a steep learning curve. If you truly want to understand the technology, you need to learn a lot of computer science and calculus and most people are not good at either.
So those who know just 1% more than others can successfully sell themselves as influencers or educators while being technologically inept. This leads to inflated expectations by believing the oversimplified — or even factually incorrect — bullshit preached by these people.
During my work, I talk to a lot of CEOs of organizations both small and large. They come to me usually with these inflated expectations, asking for fully autonomous AI agents and we end up talking about and building the most basic automations.
Organizations are still behind in adopting AI in their lives. Employees are learning how to think differently. Unfortunately, prompt engineering ended up being a misdirection. It doesn't matter how well you engineer your prompts if you can't think efficiently about the problems you're trying to solve.
We have no idea how to make good use of even simpler models too. Just look at my analysis of productivity from my post in August. A lot of those statements still hold true.

In 2024 we went from GPT-4 to 4o to o1 to o3.
This is an incredible pace of development and it doesn't seem to be slowing down.
In 2025 we will see more development in the technology front but adoption will keep lagging behind. If patience runs out in the boardrooms, organizations might give up and write down AI as just another fad, bringing us a new AI winter. It wouldn't be the first one.
Of course, those organizations who don't fall for this trap and do the work of rewiring their business to successfully adopt AI-powered workflows will gain the edge and outgrow others. But that will be the minority. (For these businesses, I'll be here to help).
In other words: The world is not ready for o3 yet.
PS: I wish all of you a very Merry Christmas. I hope you have an amazing time with your loved ones, get some rest, and break away from this madness. The real world happens when your computers are turned off.
I’m grateful for having you here on my list and following this journey. Through writing about these things I also learn a lot. Thank you for your support! ❤️
I’ll be back in January with a lot of changes and ideas so watch out. If you have any requests that you’d like me to write about or build, drop me an email or a DM on Substack.
Exceptional piece. Well done!
Yes the distance between model capabilities and what most companies are able to do - because things are always messy in organizations is still huge