
The no-code guide to building AI agents
You don't need to code but you need to think

No-code is awesome. I have a standard way for choosing my stack for each project. In this post I’ll explain what I use, how and why. I also explain what’s not an AI agent.
Let’s start with a definition: Level of Abstraction.
This represents the amount of complexity by which you build a system. The higher the level, the less detail. The lower the level, the more detail.
Every time I work on something new, I ask myself:
“What level of abstraction does this project need?”
This allows me to think through the problem and remove unnecessary details. For each level of abstraction, I use a different toolkit.
Abstraction determines complexity. You manage complexity with control flow which is the order in which you want to do individual tasks.
I work with cognitive workflows, where I inject LLMs and agents into internal processes. My job is to figure out where and how to apply LLMs to make work better.
For this I usually distinguish between Tasks, Workflows, Processes and Agents.
Task Level
A task is the smallest, actionable unit of work. Specific, repeatable and measurable. Limited scope with no dependencies beyond immediate inputs and outputs. Your control flow is sequential: Steps follow one another in a linear fashion.
A few examples:
Write an email response
Parse a JSON file
Download an email attachment

If you only want to stay at this level, here are a few tools to use:
Zapier, because its simple, linear UI allows for simple task automation. It also has over 6000 app integrations so you don't need to get technical.
IFTTT, same as Zapier, but it's even simpler. If this, then that. If you're an absolute beginner, start with this one.
You reach the limit of this when you realize you need to add some filters based on some extra data. This is when you get to the Workflow level.
Workflow Level
Workflows are sequences of tasks that work together to achieve a specific goal. This means that tasks connect to each other and are interdependent. Defines inputs, transitions and outputs between tasks. A workflow always has an overarching end goal and your job is to figure out how to achieve that.
Let's say you're signed up to a newsletter. Their content is great, but they are full of ads and irrelevant clutter that makes it hard to read. You want to strip the email to its bare-bone, plain text and read only that. It's not a simple "if this, then that" task. In fact, it's several tasks.

A few other examples would be:
Scrape news from RSS and create a daily digest
Rank emails based on urgency using AI
Transcribe a meeting recording, itemize them and upload to Monday
At this level you need a bit better control flow to achieve a higher level of complexity. You can achieve this with filters and branches. This tells your program to "only continue if condition X is true."
Here's what I use at this level:
Make, because its Flow Control modules are potent enough for this level. I can manipulate data with iterators and aggregators. I can also determine the order of things with routers and filters.
Airtable or Google Sheets, because I sometimes need to save data or status.
For example let's say I'm collecting all AI-related news articles from the NewsAPI. I filter them through an LLM that knows what's important to the Lumberjack community. The ones that pass get a summary and sent to Discord to the #news channel.
I want to run this daily, but I only want to process news that are not processed yet. I need four things to make this work:
Have a table in Airtable (or Google Sheet) that contains all articles I've processed.
Once I collected a news piece from NewsAPI, check if that URL exists in my Airtable or not.
Set up a filter to only let things through if the URL is not in Airtable.
Save the URL to Airtable once the scenario finishes.

At this point we're reaching a higher level of complexity. In some cases filters and search work well together. In other cases you need to have a "status" column and set it to "done" at the end of your scenario. But sometimes things become more complicated and you need more.
Is this an AI agent? Just because a task or a workflow uses LLMs, it’s not an AI agent! Anyone that calls a simple Make scenario an AI agent is incompetent or lying.
Process Level
When you bring many workflows together, you get a process. This creates a larger framework to achieve strategic objectives. You need to define what you need to achieve and why. You need to incorporate feedback loops and decision points. Filters are not enough anymore, you need better control flow.
This is when you introduce loops and subroutines. Loops tell your program to keep doing something until it meets a certain condition. Using our previous example, we download 30 news pieces from the last 24 hours from NewsAPI. Then Make runs a loop:
For every news piece it downloaded (Make calls these packets of data bundles), it will run the scenario. The scenario keeps running until it runs out of news pieces (after processing all 30).
Using pseudocode, this is what it looks like:
news_articles = fetch_from_newsapi(last_24_hours)
for article in news_articles:
process_article(article)
Make handles loops at a scenario level. If you have a more complicated program, you will need loops.
But you can't define loops in Make, only with very complicated workarounds. It only makes sense to use those workarounds if you don't understand loops. But figuring them out takes more than learning loops, so don't do it.
Instead, use n8n, because:
It's like Make so your learning curve won't be as steep if you know your way around Make.
It can handle all control flows including loops, filters, subroutines, coroutines, etc.
You can self host it versus Make's operation-based pricing.
It can handle cognitive architecture natively (more on that later).
Here's an example. This is a n8n workflow made by Akram Kadri, which scrapes business emails from Google Maps. It doesn't use any third party APIs at all and contains a few loops.
In Akram's workflow, you need to define search queries, so the workflow knows what it needs to collect. This example has 14 queries altogether. We will need to run the whole workflow for EACH query.
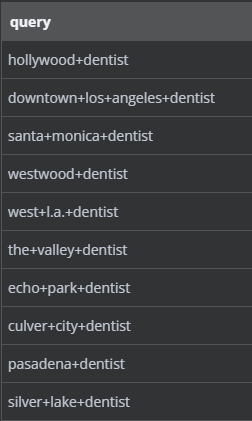
To achieve this, Akram set up a simple loop. It says: "for every query, run the scraper and wait 2 seconds, until you run out of queries."
This is how it looks like in n8n:
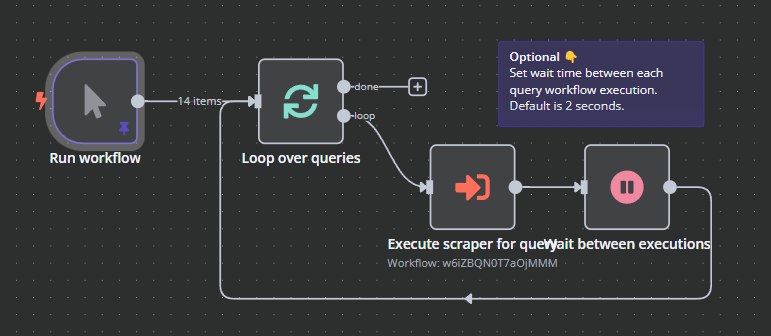
But wait, what's that scraper thing? It's a subroutine. In Make, you would need to make a separate scenario and trigger it with a webhook. In n8n, you can handle it within the same workflow. This makes it a lot easier to manage more complex programs.
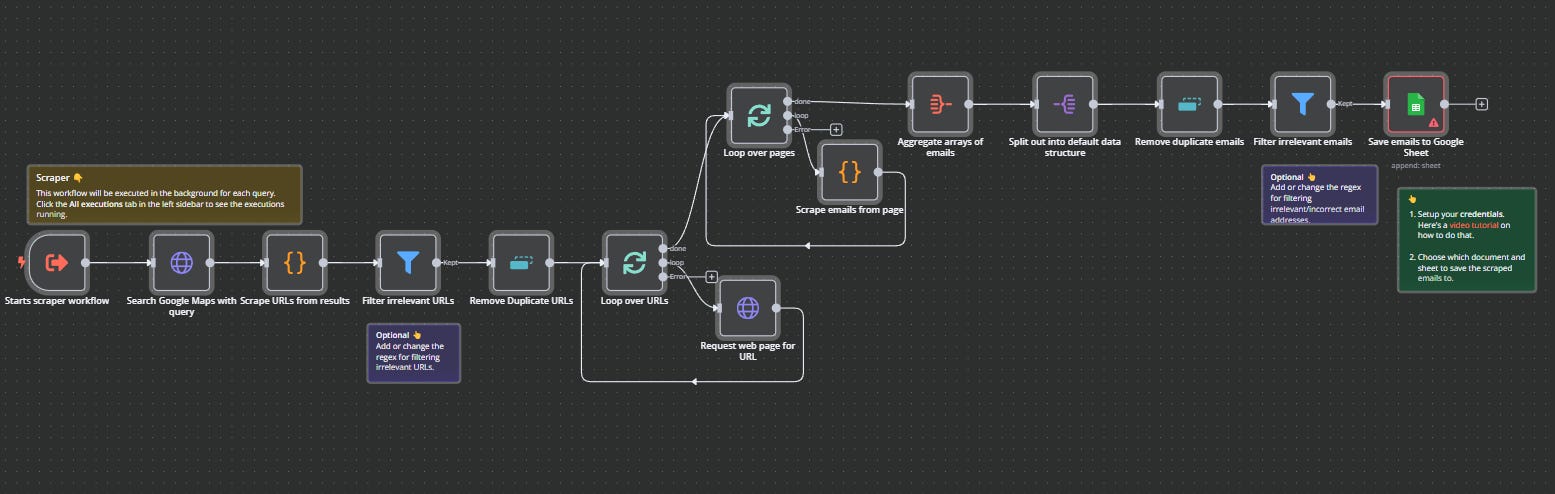
The scraper workflow looks like this:
Search Google Maps with the query
Scrape the URLs from the result and clean them
Loop: for each URL, request the web page AND for each web page, scrape emails. This is a nested loop. If it scrapes lumberjack.so, it will scrape ALL pages. then it will go through EACH page and save any email addresses it finds there. Once it's done, it moves on.
It collects all emails, structures and cleans them.
Then it saves the rest in Google Sheets.
Building the same process in Make would've taken several scenarios. In each scenario you would've needed to save "status" of the process at different levels. N8N handled this all better. If you want to use this specific workflow, Akram made a tutorial video about it.
Is this an AI agent? No, this is a piece of software that’s a bit more complicated. The above example doesn’t even use LLMs. It can still use LLMs but it won’t make it an agent.
Agent Level
As you can see each process is somewhat linear. The decisions your programs are making are deterministic and logical. This is why they're nothing more than a complicated, nested "if this, then that" logic.
Up until now you had three options to decide whether a task, workflow or process should run:
Create a logical rule (the if part of if this, then that)
Create a schedule (run once every day)
Run it yourself (manual trigger)
When you need to trigger a task, workflow or process yourself, it's because you need to make a decision. Especially if you need to make a qualitative decision. Like whether a piece of content is relevant enough.
Now we're adding a fourth option: an agent (finally!).
Agents operate at the highest level, encapsulating your tasks, workflows and processes. They don't do them, but they decide what to run.
Because of this, agents are never "pure AI". They need deterministic software to run.
Based on how complicated your requests are, you can think of narrow agents and open agents. Narrow agents can only decide on simple things like "is this content good enough? If yes, schedule it, if no, rewrite it". Open agents can do much more, like "Cold call this lead and book a sales meeting."
I write a lot about the dilemma between narrow and open agents. In fact, that was one of the first bold statements I made in my very first article.
At the end of the article I claimed that:
[…] all we have for now are narrow agents designed around compartmentalized workflows to ensure that automated and human parts of a workflow have seamless transfer of context.
In other words:
You need to build narrow agents and not open agents if you want business results.
Now is the time to go a bit more technical and explain why.
Let me show you a simple personal assistant agent that runs on n8n and handles simple tasks. Derek Cheung made this. Here's where you can find the template and here's the tutorial.
(Disclaimer: The images are from my local n8n instance. I set it up just yesterday and I haven't set up my credentials yet. This causes the red triangle error icons.)
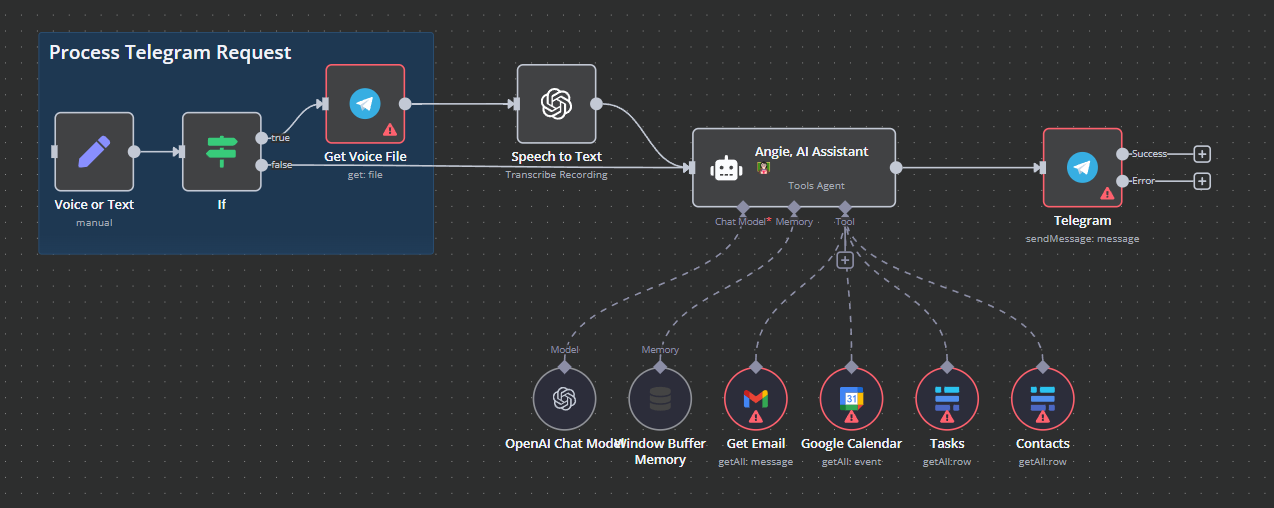
Derek calls this assistant Angie, which works through Telegram. A simple trigger listens for Telegram messages. If it receives a voice message, transcribes it with Whisper. Once done, Angie gets the message.
If you read my post on AGI, you'll know I ended it with the AGI trifecta. This is what every AI agent needs to cover to some degree.
Multi-agent AI can indeed tackle complexities LLMs can’t. [...] you’re achieving System 2 thinking at an architecture level.
Let’s see what we have here:
Memory
Tools
Reasoning
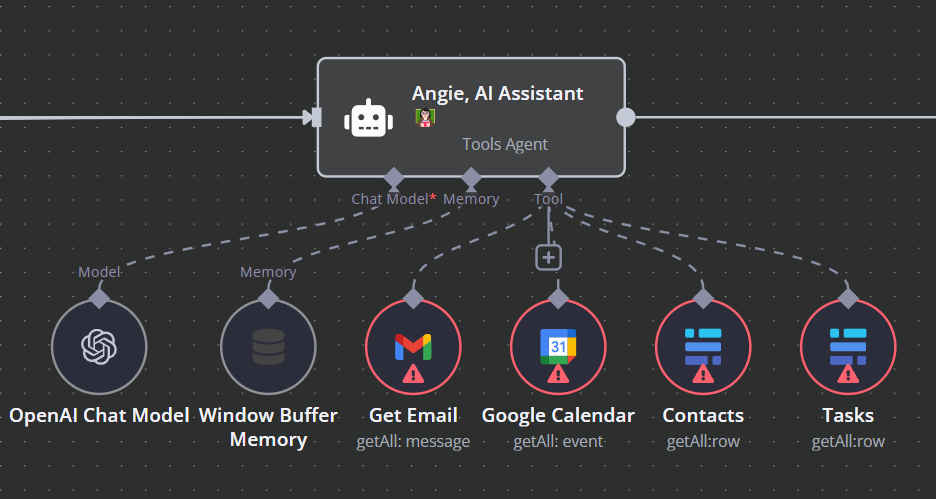
Derek’s assistant seem to have all three.
Reasoning: Since Angie is a simple narrow agent, it's reasoning is a simple OpenAI chat model. It doesn’t actually reason per se but it can simulate it good enough.
Memory: Since we don't need sophisticated memory, we can avoid the whole RAG and Knowledge Graph issue. Instead we can use a buffer memory, n8n handles that for us.
Tools: Then we have a few simple tools Angie can use, like check emails, calendar events, tasks or contacts. N8N has a bunch of built-in tools which makes our lives easier.
Based on your message, the chat model decides which tool to use. It performs the action and sends it back to the chat model. Then based on the data the chat model drafts a response and sends it back to Telegram.
As long as your tool is set up you shouldn't have any issues with hallucination or similar.
If you read my article on creating Alfred, you're probably wondering if I want to build Alfred the same way. The answer is yes.
But in some cases you will need more reasoning than just making a decision. You need a step by step thought process. This is when you would create multiple agents that talk to each other. Each agent has its own set of tools.
Here's an example of an agent that can handle more complex scenarios:
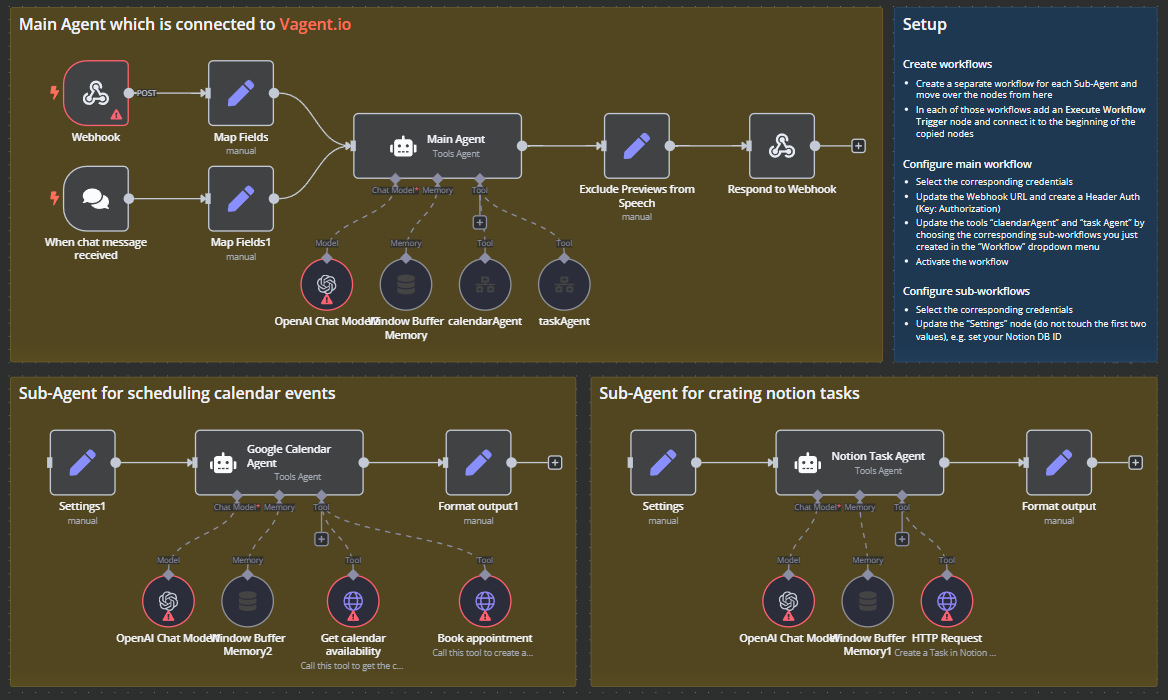
Mario Haarmann at Octionic built this. Here's a Youtube tutorial on it.
This agent represents the current last tier of control flow: orchestration.
You have more than one AI agents but you only talk to one. That is your orchestrator or in this case the Main Agent. Then the Main Agent decides which agent to call, which will carry out a task.
This compartmentalizes problems to a level of abstraction that these models can do. In this case, you have a nested agent: the orchestrator talks to agents.
In more complicated cases, you would have orchestrators that talk to sub-orchestrators. This can go on forever until you end up having hundreds of agents running. This needs careful cognitive architecture, because it can become quite expensive.
This is why OpenAI's GPT-4o-mini and Groq are so impressive. The cost per token is so low, your level of complexity can go up.
But building these things is very hard. You're hardcoding intelligence and decisions. This is necessary because models cannot reason themselves. AI currently cannot follow actual logic. You need to handle it at an architecture level.
From this point we have two options:
Science figures out some new way of doing intelligence. This way we wouldn't need to build a gajillion layers of orchestration.
We stick with the current way of doing intellingece. In this case AI industry would spend the next years with one thing. Trying to build a gajillion layers of orchestration until we achieve AGI.
Both scenarios need compute to be several times cheaper than it is. The number of LLM prompts grows exponentially which each layer of orchestration. This explains why o1-preview and Realtime APIs are expensive. Or why everyone is going crazy about creating more chips.
giving insight into the playbook for free.. well, that my friend, that's main character energy. 😎🙏🏾
Wow, I've never used n8n before, but subloops are indeed an issue in Make.com. Thank you for your insights, David!