

Last night OpenAI launched GPT 4.5. It’s only available to Pro users, but as a developer you can also get access to it via the API, which brings us to the first realization:
GPT 4.5 is expensive
Here’s the pricing comparison:

$150 for 1 million output tokens is a LOT, especially while every other AI lab are in a race to the bottom with token costs. So why is that?
Mainly, because OpenAI is running out of GPUs. I’m not saying this, Sam Altman is.
So why is this happening? Let’s dive in. This article will have two parts:
- What is unsupervised learning?
- Where models are going?
Unsupervised learning
OpenAI focused their pitch around unsupervised learning as a key differentiator versus reasoning models. As their website says in the GPT 4.5 announcement post:
We advance AI capabilities by scaling two complementary paradigms: unsupervised learning and reasoning. These represent two axes of intelligence.Scaling reasoning teaches models to think and produce a chain of thought before they respond, allowing them to tackle complex STEM or logic problems. Models like OpenAI o1 and OpenAI o3‑mini advance this paradigm.Unsupervised learning, on the other hand, increases world model accuracy and intuition.
The process of unsupervised learning is not new and it’s not even unique to LLMs. It’s a well-known training method in machine learning. Let’s say you have a bunch of kids at a birthday party. They have to select from a list of games and decide what to play.
You have 100 kids at the party, it’s a big one, so you’ll need groups of 5-8 kids. You ask every kid what they want to play with and what they hate. Based on the responses, you need to assign them to groups.
Instead of doing it manually, you run a machine learning algorithm called unsupervised clustering. This means that in a recursive process the machine is trying to create groups that are distinctly unique. It will keep running and keep creating new groups until it cannot optimize it even further. When it’s done, you print the names that belong to each group and the games begin.
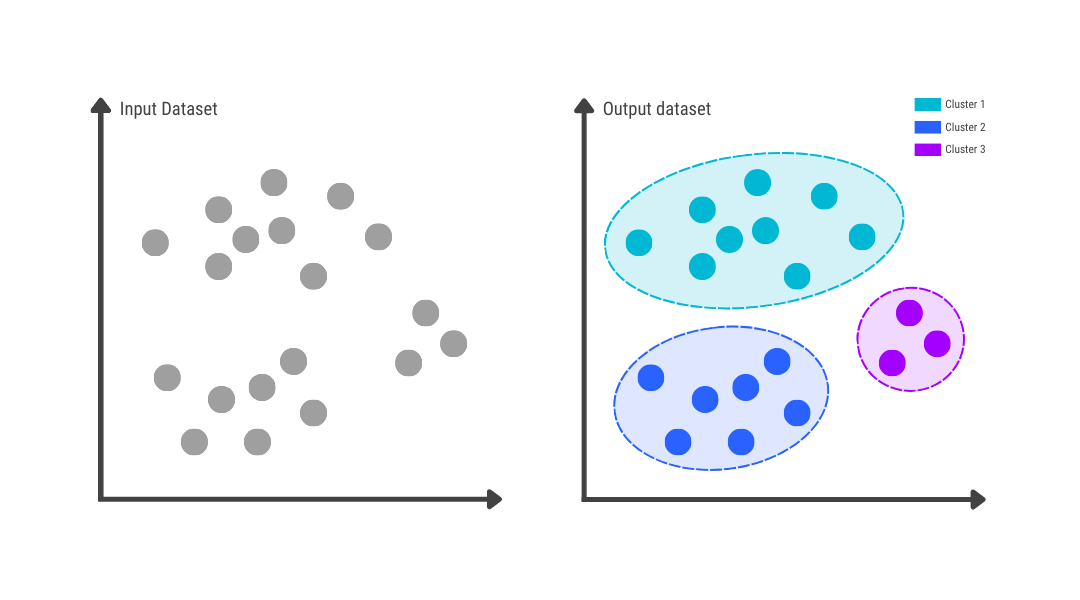
This approach saves a lot of time, but it only works if your dataset is relatively structured. Human language is very unstructured compared to computer code so before Transformers (the tech that runs GPT models), it wasn’t really possible to use unsupervised learning for natural language text. Basically, the less clean your data is, the less accurate your unsupervised learning models will be, because they don’t have any self-correcting mechanisms. This will be important later.
This is why GPT models are a big deal. By the time 3.5 came out, it became clear that this special kind of unsupervised learning gets better and better as you keep giving it more processing power. It’s very hungry for data and it’s very hungry for compute hours but provided you have plenty of both, you can build a GPT-4 type model.
Is there a wall?
Then GPT-5 never came. We heard rumors about Orion, Strawberry, they introduced a whole new family of “reasoning” models, but something have happened.
Altman says that GPT-5 won’t be a model, but instead a system and that gives us a clue. Simply put the arguments are:
Unsupervised learning in transformers scales intelligence as a function of the data and the computing power available.
If development slows down, that means one of three things:
You ran out of data
You ran out of computing power
The scaling trend is slowing down (a.k.a.: “there is a wall”)
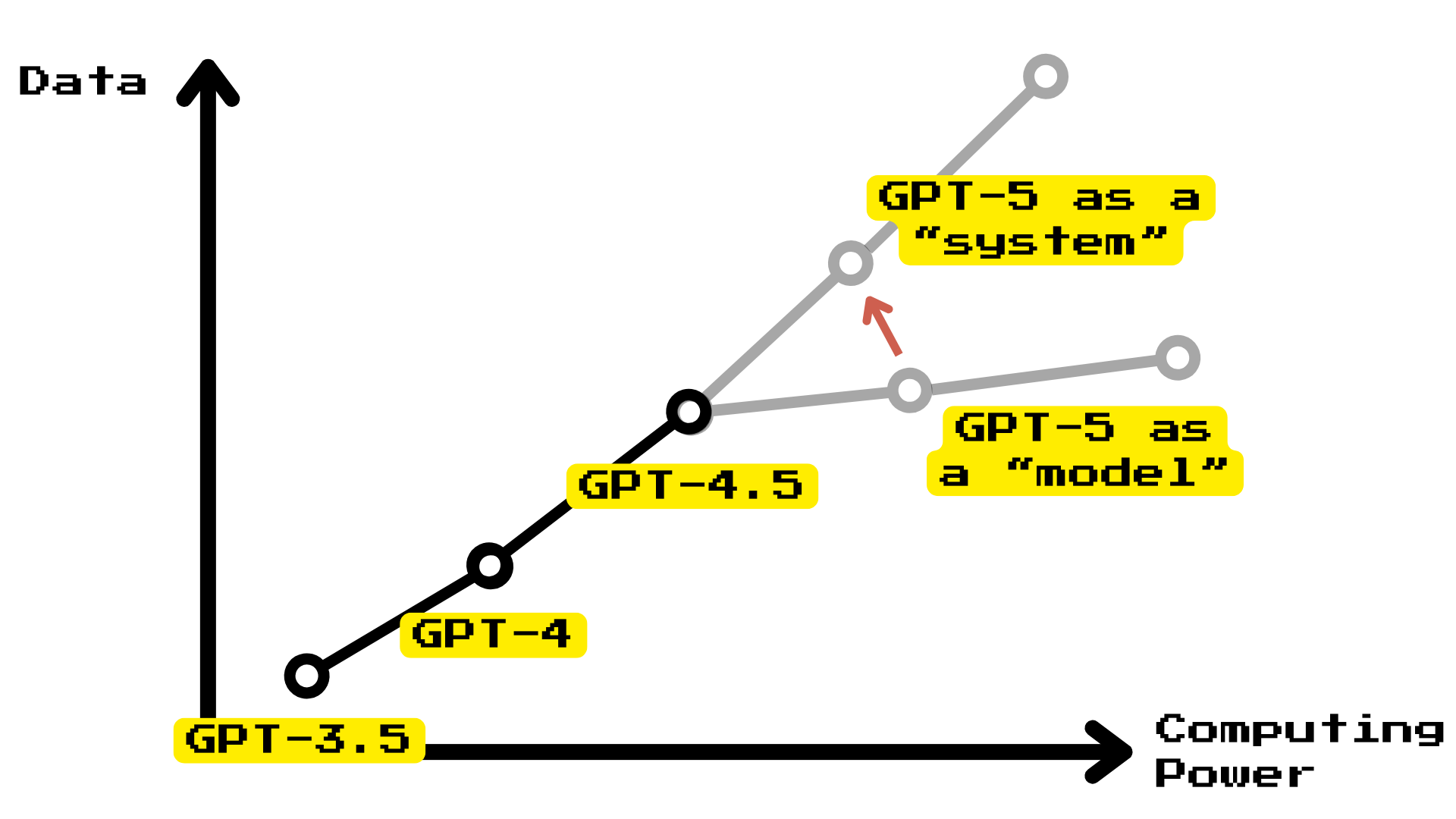
So to mitigate this, Altman announced that GPT-5 won’t be a model but a system:

So the only question remains is: did they run out of data, GPUs or found a flattening of the scaling law? We don’t know yet, but GPT-4.5 is interesting because of a lot of things.
Self-distillation
The only thing that GPT-4.5 really differs from its predecessor is its ability to self-distillation during training. Remember what was the biggest pitfall of unsupervised learning? That bad quality data messes with its accuracy, because it cannot self-correct?
Well, OpenAI figured out how to inject this self-correcting mechanism into the training process. So when they trained GPT-4.5, they didn’t just train a bigger model, they forced it to reevaluate every response it generated. This is like RLHF (reinforcement learning based on human feedback) but the feedback is done by the model itself. This process is called self-distillation. This recursion created a really interesting phenomenon:
GPT-4.5 is noticeably dumber than o1 or o3. But it seems to feel more human.
So looks like the argument OpenAI is trying to make now is that GPT-4.5 has a higher emotional intelligence. That’s convenient because that’s very hard to measure even in humans let alone AI models.
Assuming there’s enough data and computing power (which is what Altman has been making sure to secure for the last two years), there’s no evidence of a limit to how intelligent you can get.
You just have to scale the level of self-distillation and scale the reasoning tokens. This is what OpenAI’s Chief Research Officer Mark Chen said, when asked:
[…]we now have two different axes on which we can scale. So GPT 4.5 is our latest scaling experiment along the axis of unsupervised learning. But there's also reasoning. And when you ask why there seems to be a little bit bigger of a gap in release time between 4 and 4.5, we've been really largely focused on developing the reasoning paradigm as well.
So: training = knowledge, reasoning = intelligence. Gotcha. Mark says:
You need knowledge to build reasoning on top of. A model can't go in blind and just learn reasoning from scratch. So we find these two paradigms to be fairly complimentary, and we think they have feedback loops on each other.
Are we slowing down?
The only attribute OpenAI cannot directly have an impact on is how fast GPUs get. That’s Nvidia’s realm. But what OpenAI must have realized in the last year or so is that creating artificial intelligence happens on a multi-axis playground.
They will likely end up building a reasoning system that generates tons of synthetic data, which can scale unsupervised learning even further. Running out of data is a big problem and a hard constraint to develop better models and we’re running out of data. If anything this might be a wall that needs to be mitigated somehow. That our AI systems have gobbled up all of humanity’s data.
Then later—as GPUs get more powerful—they can go from reasoning 10k tokens to reasoning 1M tokens. Then put that reasoning output into training a new, bigger model. Then rinse and repeat until AGI.
This is what Gary Marcus thinks is stupid, because it doesn’t address fundamental issues (lack of symbolic logic). It just keeps throwing money and data at the same problem.
To be fair, we have no proof that this rate of development will hit a wall.
But we have no proof it won’t either.
One thing is for sure. This game just got a lot more complicated. This is what GPT-4.5 is truly revolutionary at. It highlights how inference (reasoning) and training (self-distillation) relate to each other. If the researchers find their footing quickly in this new paradigm, the rate of development will not slow down at all.
But soon we’re going to reach a point when this development is faster than how cheap and fast token generation gets. This is probably also the reason why GPT-4.5 is so damn expensive.
That is currently the most likely scenario in which development might stall.
