
Alfred, my AI butler - Progress Update
What makes one butler smarter than another.

tl;dr: Here’s everything you need to know about cognitive architecture to build your own AI agents.
If you’ve been following my work, you're probably aware that I’m focusing a lot on figuring out how to create meaningful content with AI.
My app, High Signal is built on a simple concept borrowed from sound engineering:
Signal to Noise Ratio (SNR)
Here’s more info on this:

I’ll explore the depths of SNR in future posts, but here’s one concept that was critical for High Signal to work: scaling test-time compute to appropriate levels for the task at hand.
Training-based Intelligence
The arrival of o1 signaled a new kind of intelligence for AI. Before o1, the only way to get smarter models was to feed them more data during training.
When you were using an LLM your experience was pretty straightforward:
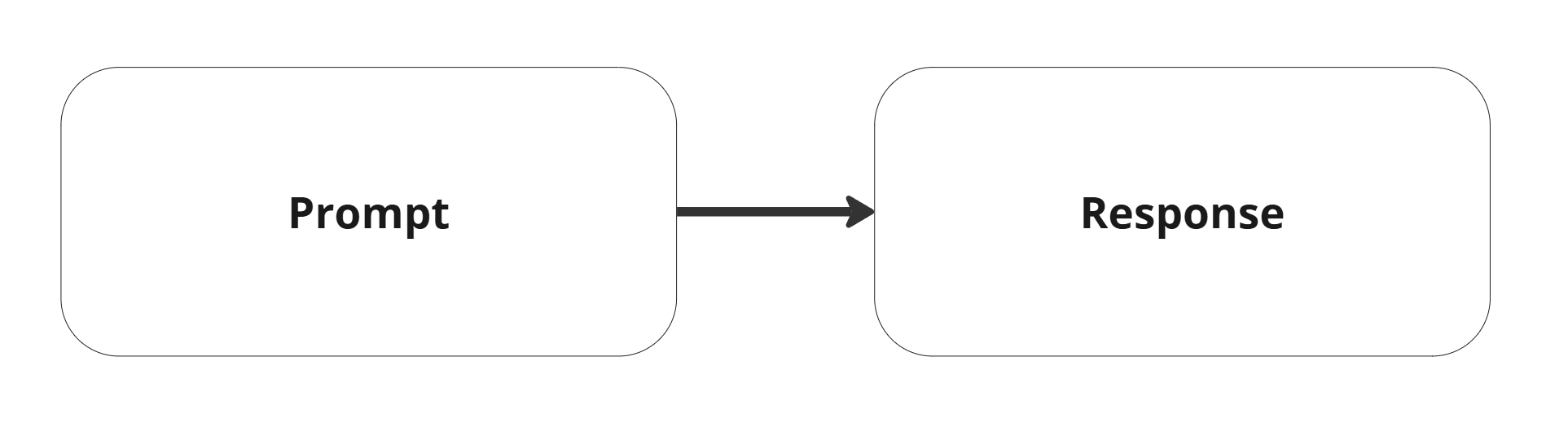
Then really quickly people realized that you can use conversation design to create longer conversation with LLMs that will in turn increase the quality of responses. Basically, if an LLM doesn’t produce a great answer first, keep talking with it until it does. It’s just a bunch of prompts and responses connected by a single thread.
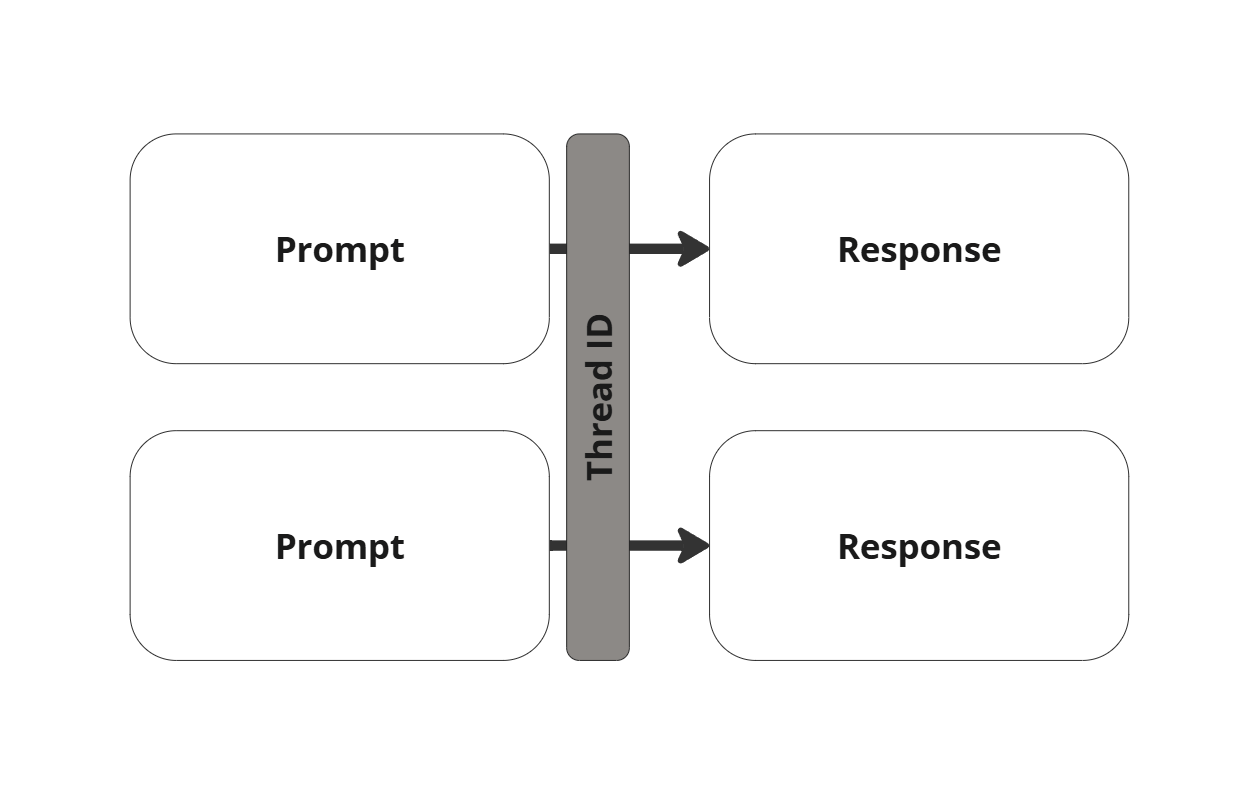
Inference-based Intelligence
Then o1 started to “reason”. Before generating a response, it first contemplated on what the user wanted. Then everybody went a bit nuts at Christmas for o3, then especially when DeepSeek seemingly shat the bed upset everyone with R1.
I’ll ignore all this because it’s been covered well and jump straight to s1. (Github, arXiv)
An open source cognitive architecture for test-time scaling that also beats o1 for a few dollars of inference.
If you don’t want to read the whole thing, here’s how it works:
Whenever you call a model, instead of generating a response immediately, you first allocate a token budget to contemplate and think about the user’s request. When the allocated token budget runs out (so the model generated enough thinking tokens, it force stops that process and sends everything to a new LLM call that will generate a response.
Here’s the architecture as a n8n workflow:
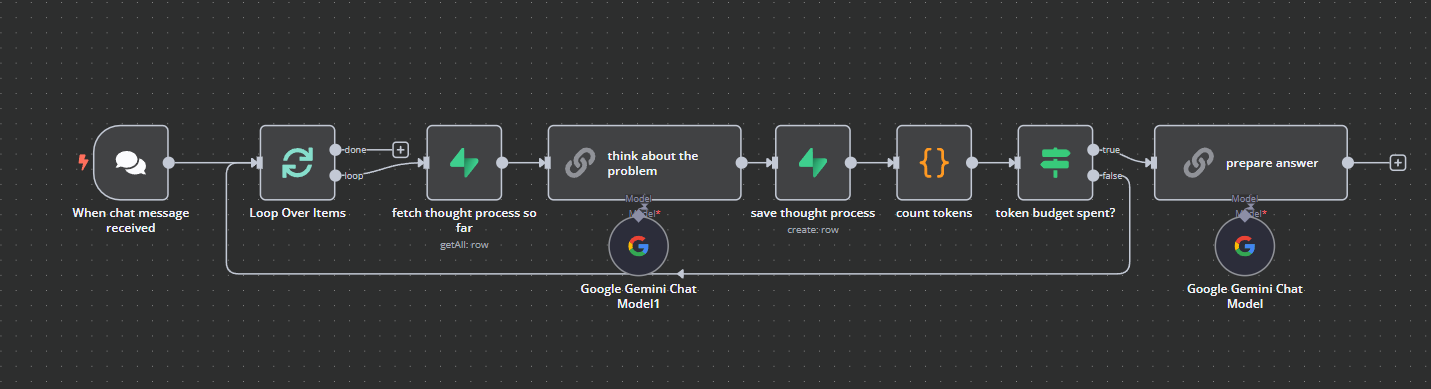
Now, with this architecture you can use simple models like gpt-4o or llama and achieve o1 level performance at a fraction of the cost.
The exciting part is that the more tokens you allow the model to generate, the better the responses will be.
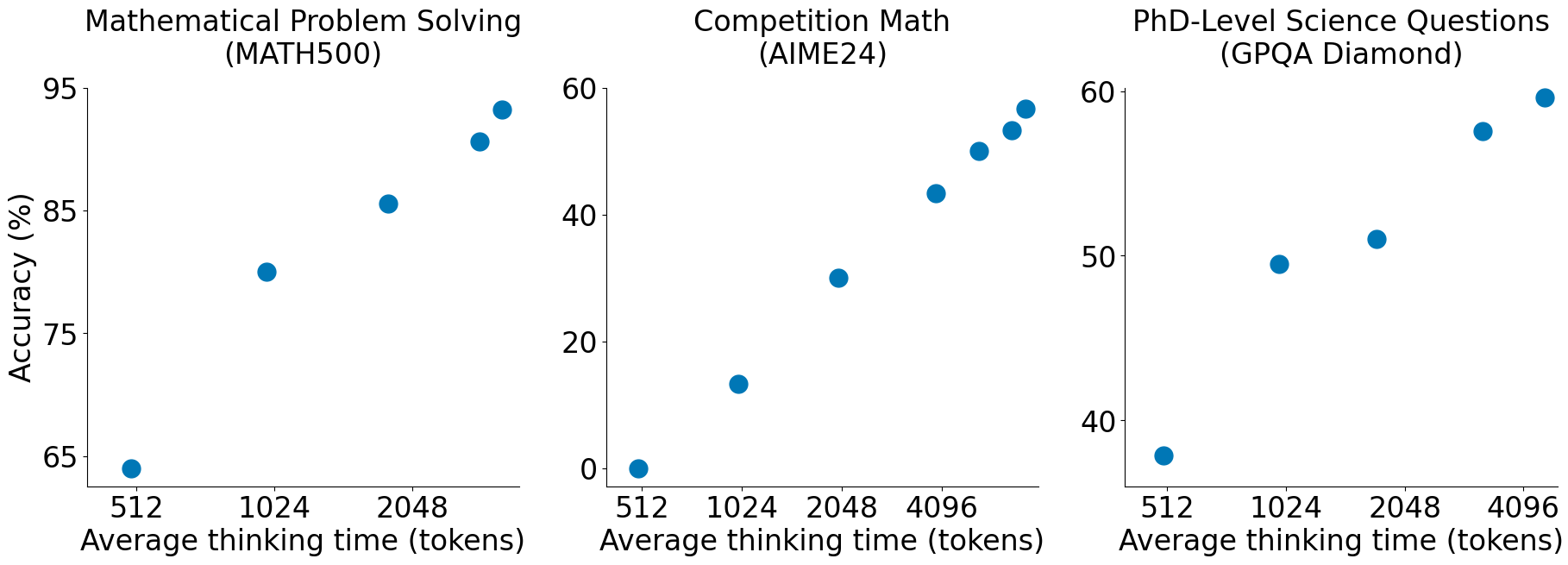
The technique it’s using is called budget forcing. You determine how many tokens can a model generate by thinking, and when it runs out, it forces a response.
It’s so blatantly simple, yet brilliant.
Now we know a few things about using LLMs:
LLMs need extensive context to generate good responses.
LLMs can generate their own context which we call “reasoning”.
Scaling reasoning tokens scales output quality.
Basically, you just need to figure out how long does a model need to think to solve a problem and you’re good. Resources constraints will force you to be creative on the prompts you use and the data you pass on to the model, but apart from that, this is good enough.
Levels of Agency
The other big topic is the topic of agents. A few folks at Hugging Face, led by Margaret Mitchell just published an article on arXiv. In this article they argue that fully autonomous agents shouldn’t be deployed. I agree.
Based on Roucher et al they introduce a 5 level classification system for AI agency.

This finally gives us the right scope to think about AI agents.
Not everything is an agent.
Here’s an example of how a Level 3 agent works:
Alfred v1.0
Here’s where I’m at with Alfred right now.
If you haven’t a clue what that is, read this article:

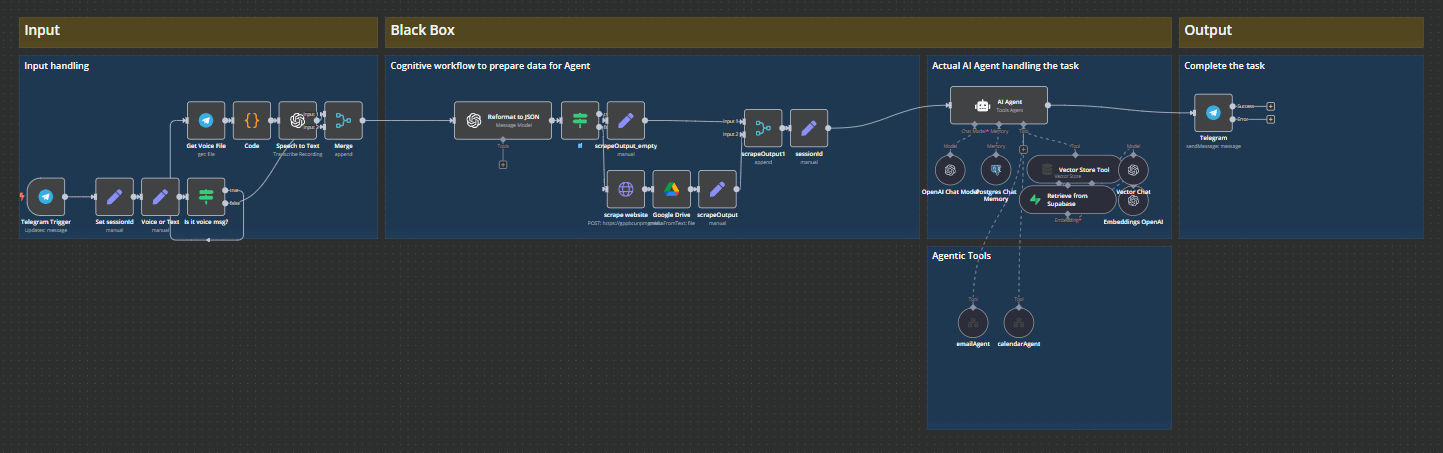
Alfred exists as a Telegram bot so Input can be Telegram message or Voice message.
There is only one thing that I hardcoded in the process and that is when I send a URL to the bot. You’ll see in “Black Box” that when I send a URL to the bot, it recognizes, extracts the URL from the message and sends to a scraper that lives as a Supabase Edge Function. The output is then saved to a Google Drive folder.
The agentic part comes at the third column:
All the text is then sent to an AI Agent node in n8n. This node has the following:
gpt-4o as a chat module
a Supabase Postgres table as short term memory (last 10 messages)
a Supabase Vector Store using OpenAI Embeddings for long term memory
an
emailAgentand acalendarAgenttool
When you look into the emailAgent tool here’s what you see:
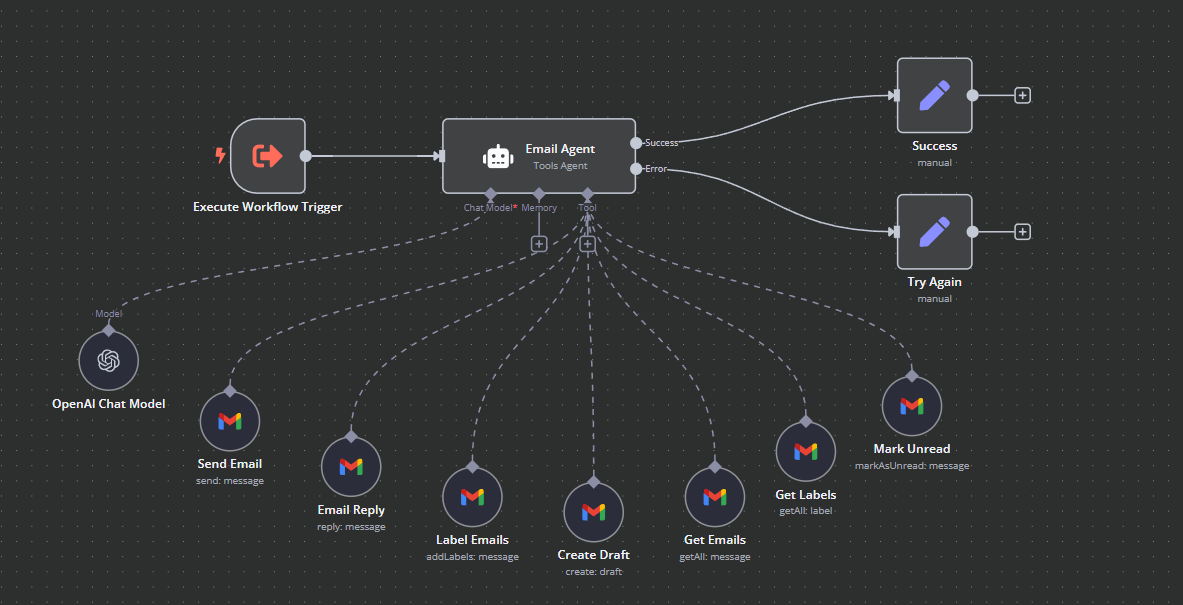
What does this mean exactly?
It means that Alfred as a whole is only a Level 3 Agent: It’s one job is to make tool calls.
By creating another simple tool call Level 3 Agent (emailAgent) as one of Alfred’s own tools it can call, I basically elevated Alfred to Level 4 at an architecture level.
Just like what s1 did to gpt-4o, this is how a good cognitive architecture can increase output quality.
Currently Alfred can manage all my emails and calendars, it can find my friends’ email address and craft a message, find my availability and send calendar invites for others, etc.
All I need to do is keep plugging in more tools as agents and if it gets too complicated, I can keep breaking it down.
Agentic Architecture
Now that we covered test-time scaling and levels of agency, there’s just one thing left to do. To put all of it together, trying to imagine what a Level 5 Agent would look like.
Here’s my take, explanation below.
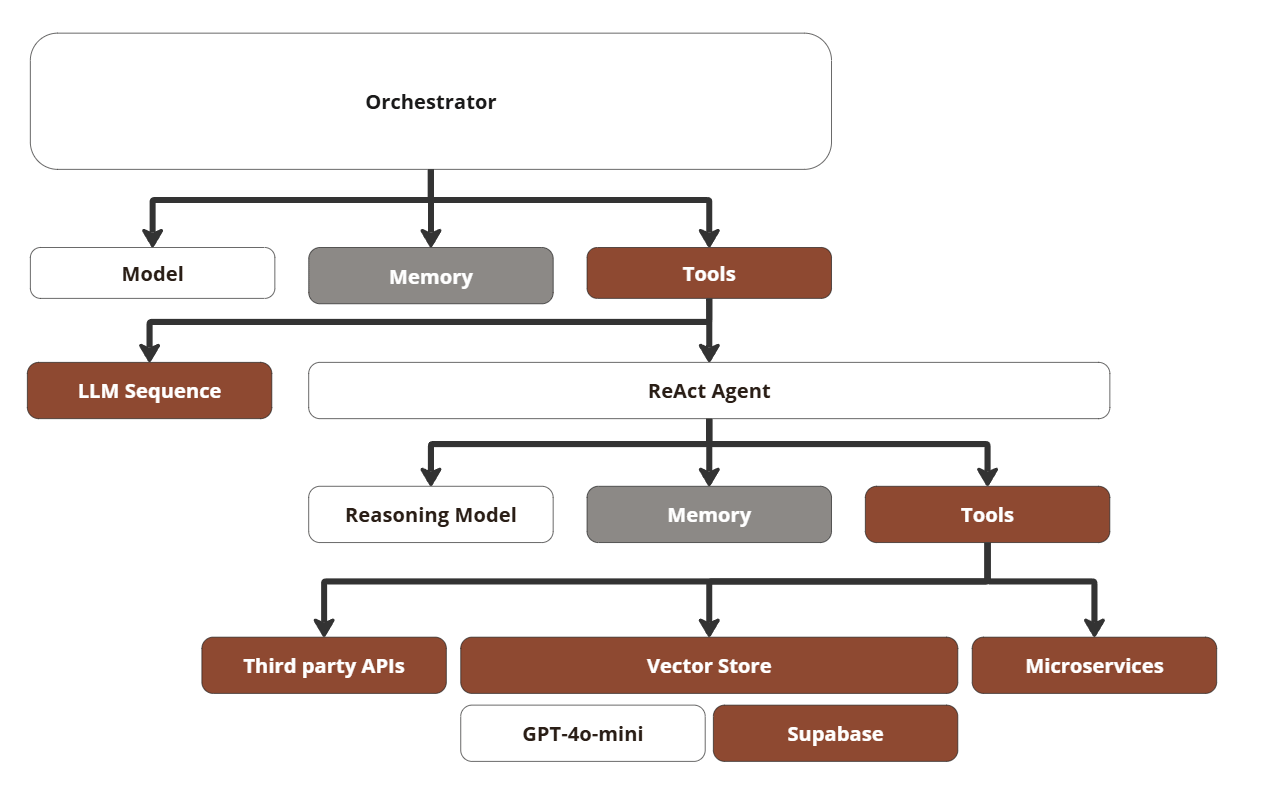
You talk to an “Orchestrator” agent that’s operated by gpt-4o level LLM (or even finetuned to achieve a certain tone of voice). The Orchestrator is a Level 3 tool call agent that calls different tools.
LLM Sequence tool for more deliberate thinking with higher token budgets. Think the test-time scaling but at larger token budgets. This means that when you ask the Orchestrator to "think hard” on something, it will pass the task onto this LLM Sequence. This runs a simple Level 2 router agent for test-time scaling.
“ReAct Agent”. This is short for reasoning and action which means it uses a Reasoning Model (or you can replace that by a simple s1-type architecture) to decide which tools to use. Just like the Orchestrator, this one also is just a Level 3 tool call agent.
The ReAct agent can call a vector store for retrieval or call third party APIs or even custom microservices. In the above example, these services would be Gmail features.
This means that when you send a request to the model (“Find Charles’ email address, check my calendar and propose three timeslots for a call next week via email“), the Orchestrator checks what you want, calls the ReAct agent that will fetch the necessary context for itself, then call the relevant microservices (email and calendar), then send back the information to the Orchestrator. Then the Orchestrator sends the data back to the LLM Sequence to think hard about what to propose, then once done, it sends everything back to the Orchestrator.
Then the Orchestrator calls the ReAct agent again to write and send the email based on what the LLM Sequence said. ReAct sends off the email, pings the Orchestrator which then sends you a message:

Hey there, fellow experimenter with cognitive architectures here. Love your Alfred experiment and I have been experimenting with many similar things, more focused on the memory than tool calling aspect for now. One thing I’ve noticed is that the orchestrator you mention really really benefits from beeing > gpt-4 Level Model. There is lots of subtlety you want captured here and often it’s not many tokens so it’s really worth it to use the best available model at critical points in the system (like orchestration). Also there can be a sort of fractal system where any module can spawn an entire new agent if it turns out a given task is too hard on its own. Also if you turn this into a full on assistant I would recommend progressive summarisation over just using retrieval for long term memory as well :) Anyways great post!